temporal_graph_networks
The temporal_graph_networks (TGNs) are a type of graph neural network (GNN) for dynamic graphs. In recent years, GNNs have become very popular due to their ability to perform a wide variety of machine learning tasks on graphs, such as link prediction, node classification, and so on. This rise started with Graph convolutional networks (GCN) introduced by Kipf et al., followed by GraphSAGE introduced by Hamilton et al., and recently a new method that introduces the attention mechanism to graphs was presented - Graph attention networks (GAT), by Veličković et al. The last two methods offer a great possibility for inductive learning. But they haven't been specifically developed to handle different events occurring on graphs, such as node features updates, node deletion, edge deletion and so on. These events happen regularly in real-world examples such as the Twitter network, where users update their profile, delete their profile or just unfollow another user.
In their work, Rossi et al. introduce Temporal graph networks, an architecture for machine learning on streamed graphs, a rapidly-growing ML use case.
About the query module
What we have got in this module:
- link prediction - train your TGN to predict new links/edges and node classification - predict labels of nodes from graph structure and node/edge features
- graph attention layer embedding calculation and graph sum layer embedding layer calculation
- mean and last as message aggregators
- mlp and identity(concatenation) as message functions
- gru and rnn as memory updater
- uniform temporal neighborhood sampler
- memory store and raw message store
as introduced by Rossi et al..
The following means you can use TGN to predict edges or perform node classification tasks, with graph attention layer or graph sum layer, by using either mean or last as message aggregator, mlp or identity as message function, and finally gru or rnn as memory updater.
In total, this gives you 2✕2✕2✕2✕2 options, that is, 32 options to explore on your graph! 😄
If you want to explore our implementation, jump to
github/memgraph/mage and find
python/tgn.py. You can also jump to the download
page, download Memgraph Platform and fire up
TGN. We have prepared an Amazon user-item dataset on which you can
explore link prediction using a Jupyter
Notebook
What is not implemented in the module:
- node update/deletion events since they occur very rarely - although we have prepared a codebase to easily integrate them.
- edge deletion events
- time projection embedding calculation and identity embedding
calculation since the author mentions they perform very poorly on all datasets
- although it is trivial to add a new layer
Feel free to open a GitHub issue or start a discussion on Discord if you want to speed up development.
How should you use the following module? Prepare Cypher queries, and split
them into a train set and eval set. Don't forget to call the set_mode
method. Every result is stored so that you can easily get it with the module.
The module reports the mean average
precision
for every batch training or evaluation done.
Usage
The following procedure is expected when using TGN:
- set parameters by calling
set_params()function - set trigger on edge create event to call
update()function - start loading your
trainqueries - when
trainqueries are loaded, switch TGN mode toevalby callingset_eval()function - load
evalqueries - do a few more epochs of training and evaluation to get the best results by
calling
train_and_eval()
One thing is important to mention: by calling set_eval() function you change
the mode of temporal graph networks to eval mode. Any new edges which
arrive will not be used to train the module, but to eval.
Implementation details
Query module
The module is implemented using PyTorch. From the
input (mgp.Edge and mgp.Vertex labels), edge features and node features
are extracted. With a trigger set, the update query module procedure will
parse all new edges and extract the information the TGN needs to do batch by
batch processing.
On the following piece of code, you can see what is extracted from edges while
the batch is filling up. When the current processing batch size reaches
batch size (predefined in set()), we forward the extracted information
to the TGN, which extends torch.nn.Module.
@dataclasses.dataclass
class QueryModuleTGNBatch:
current_batch_size: int
sources: np.array
destinations: np.array
timestamps: np.array
edge_idxs: np.array
node_features: Dict[int, torch.Tensor]
edge_features: Dict[int, torch.Tensor]
batch_size: int
labels: np.array
Processing one batch
self._process_previous_batches()
graph_data = self._get_graph_data(
np.concatenate([sources.copy(), destinations.copy()], dtype=int),
np.concatenate([timestamps, timestamps]),
)
embeddings = self.tgn_net(graph_data)
... process negative edges in a similar way
self._process_current_batch(
sources, destinations, node_features, edge_features, edge_idxs, timestamps
)
Our torch.nn.Module is organized as follows:
- processing previous batches - as in the research paper this will include new computation of messages collected for each node with a message function, aggregation of messages for each node with a message aggregator and finally updating of each node's memory with a memory updater
- afterward, we create a computation graph used by the graph attention layer or graph sum layer
- the final step includes processing the current batch, creating new interaction or node events, and updating the raw message store with new events
The process repeats: as we get new edges in a batch, the batch fills, and the new edges are forwarded to the TGN and so on.
This MAGE module is still in its early stage. We intend to use it only for
learning activities. The current state of the module is that you need to
manually switch the TGN mode to eval. After the switch, incoming edges will be
used for evaluation only. If you wish to make it production-ready, make sure
to either open a GitHub issue or
drop us a comment on Discord. Also, consider
throwing us a ⭐ so we can continue to do even better work.
| Trait | Value |
|---|---|
| Module type | module |
| Implementation | Python |
| Graph direction | directed |
| Edge weights | weighted/unweighted |
| Parallelism | sequential |
Procedures
If you want to execute this algorithm on graph projections, subgraphs or portions of the graph, be sure to check out the guide on How to run a MAGE module on subgraphs.
set_params(params)
We have defined default value for each of the parameters. If you wish to
change any of them, call the method with the defined new value.
Input:
params: mgp.Map➡ a dictionary containing the following parameters:
| Name | Type | Default | Description |
|---|---|---|---|
| learning_type | String | self_supervised | self_supervised or supervised depending on if you want to predict edges or node labels |
| batch_size | Integer | 200 | size of batch to process by TGN, recommended size 200 |
| num_of_layers | Integer | 2 | number of layers of graph neural network, 2 is the optimal size, GNNs perform worse with more layers in terms of time needed to train, but the gain in accuracy is not significant |
| layer_type | String | graph_attn | graph_attn or graph_sum layer type as defined in the original paper |
| memory_dimension | Integer | 100 | dimension of memory tensor of each node |
| time_dimension | Integer | 100 | dimension of time vector from time2vec paper |
| num_edge_features | Integer | 50 | number of edge features we will use from each edge |
| num_node_features | Integer | 50 | number of expected node features |
| message_dimension | Integer | 100 | dimension of the message, only used if you use MLP as the message function type, otherwise ignored |
| num_neighbors | Integer | 15 | number of sampled neighbors |
| edge_message_function_type | String | identity | message function type, identity for concatenation or mlp for projection |
| message_aggregator_type | String | last | message aggregator type, mean or last |
| memory_updater_type | String | gru | memory updater type, gru or rnn |
| num_attention_heads | Integer | 1 | number of attention heads used if you define graph_attn as layer type |
| learning_rate | Float | 1e-4 | learning rate for adam optimizer |
| weight_decay | Float | 5e-5 | weight decay used in adam optimizer |
| device_type | String | cuda | type of device you want to use for training - cuda or cpu |
| node_features_property | String | features | name of features property on nodes from which we read features |
| edge_features_property | String | features | name of features property on edges from which we read features |
| node_label_property | String | label | name of label property on nodes from which we read features |
Usage:
CALL tgn.set_params({learning_type:'self_supervised', batch_size:200, num_of_layers:2,
layer_type:'graph_attn',memory_dimension:20, time_dimension:50,
num_edge_features:20, num_node_features:20, message_dimension:100,
num_neighbors:15, edge_message_function_type:'identity',
message_aggregator_type:'last', memory_updater_type:'gru', num_attention_heads:1});
update(edges)
This function scrapes data from edges, including edge_features and
node_features if they exist, and fills up the batch. If the batch is ready the
TGN will process it and be ready to accept new incoming edges.
Input:
edges: mgp.List[mgp.Edges]➡ List of edges to preprocess (that arrive in a stream to Memgraph). If a batch is full,trainorevalstarts, depending on the mode.
Usage:
There are a few options here:
The most convenient one is to create a trigger so that every time an edge is added to the graph, the trigger calls the procedure and makes an update.
CREATE TRIGGER create_embeddings ON --> CREATE BEFORE COMMIT
EXECUTE CALL tgn.update(createdEdges) RETURN 1;
The second option is to add all the edges and then call the algorithm with them:
MATCH (n)-[e]->(m)
WITH COLLECT(e) as edges
CALL tgn.update(edges) RETURN 1;
get()
Get calculated embeddings for each vertex.
Output:
node: mgp.Vertex➡ Vertex (node) in Memgraph.embedding: mgp.List[float]➡ Low-dimensional representation of node in form of graph embedding.
Usage:
CALL tgn.get() YIELD * RETURN *;
set_eval()
Change TGN mode to eval.
Usage:
CALL tgn.set_eval() YIELD *;
get_results()
This method will return results for every batch you did train or eval on,
as well as average_precision, and batch_process_time. Epoch count starts
from 1.
Output:
epoch_num:mgp.Number➡ The number oftrainorevalepochs.batch_num:mgp.Number➡ The number of batches pertrainorevalepoch.batch_process_time:mgp.Number➡ Time needed to process a batch.average_precision:mgp.Number➡ Mean average precision on the current batch.batch_type:string➡ A string indicating whethertrainorevalis performed on the batch.
Usage:
CALL tgn.get_results() YIELD * RETURN *;
train_and_eval(num_epochs)
The purpose of this method is to do additional training rounds on train edges
and eval on evaluation edges.
Input:
num_epochs: integer➡ Perform additional epoch training and evaluation after the stream is done.
Output:
epoch_num: integer➡ The epoch of the batch for which performance statistics will be returned.batch_num: integer➡ The number of the batch for which performance statistics will be returned.batch_process_time: float➡ Processing time in seconds for a batch.average_precision:mgp.Number➡ Mean average precision on the current batch.batch_type:string➡ Whether we performedtrainorevalon the batch.
Usage:
CALL tgn.train_and_eval(10) YIELD * RETURN *;
predict_link_score(vertex_1, vertex_2)
The purpose of this method is to get the link prediction score for two vertices in graph if you have been
training TGN for the link prediction task.
Input:
src: mgp.Vertex➡ Source vertex of the link predictiondest: mgp.Vertex➡ Destination vertex of the link prediction
Output:
prediction: mgp.Number➡ Float number between 0 and 1, likelihood of link betweensourcevertex anddestinationvertex.
Usage:
MATCH (n:User)
WITH n
LIMIT 1
MATCH (m:Item)
OPTIONAL MATCH (n)-[r]->(m)
WHERE r is null
CALL tgn.predict_link_score(n,m) YIELD *
RETURN n,m, prediction;
Example
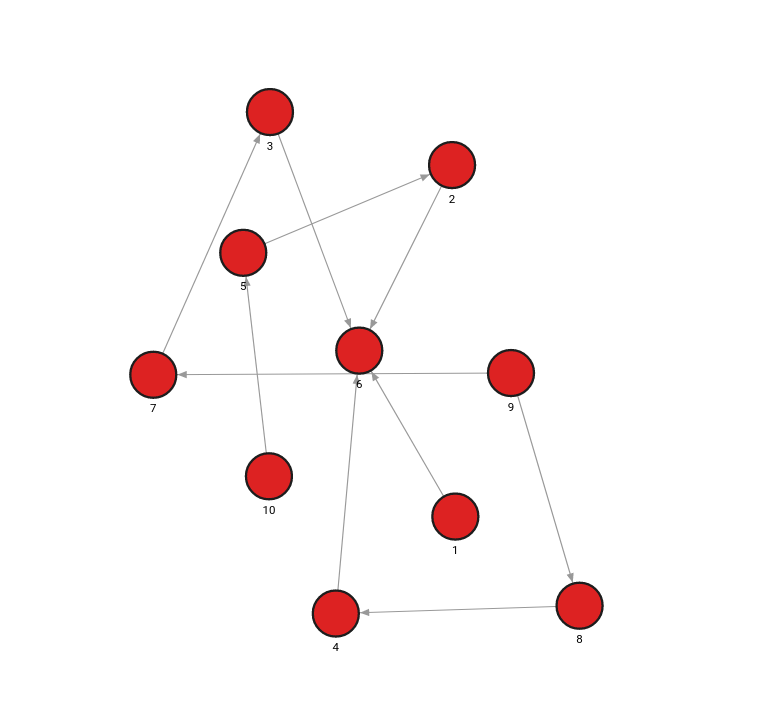
- Step 1: Input graph
- Step 2: Set parameters
- Step 3: Set trigger
- Step 4: Load training batch
- Step 5: Change mode
- Step 6: Load evaluation batch
- Step 7: Train epochs
- Step 8: Run
- Step 9: Results
CALL tgn.set_params({learning_type:'self_supervised', batch_size:2, num_of_layers:1,
layer_type:'graph_attn',memory_dimension:100, time_dimension:100,
num_edge_features:20, num_node_features:20, message_dimension:100,
num_neighbors:10, edge_message_function_type:'identity',
message_aggregator_type:'last', memory_updater_type:'gru', num_attention_heads:1});
CREATE TRIGGER create_embeddings ON --> CREATE BEFORE COMMIT
EXECUTE CALL tgn.update(createdEdges) RETURN 1;
MERGE (n:Node {id: 1}) MERGE (m:Node {id: 6}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 2}) MERGE (m:Node {id: 6}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 10}) MERGE (m:Node {id: 5}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 5}) MERGE (m:Node {id: 2}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 9}) MERGE (m:Node {id: 7}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 7}) MERGE (m:Node {id: 3}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 3}) MERGE (m:Node {id: 6}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 9}) MERGE (m:Node {id: 8}) CREATE (n)-[:RELATION]->(m);
CALL tgn.set_eval() YIELD *;
MERGE (n:Node {id: 8}) MERGE (m:Node {id: 4}) CREATE (n)-[:RELATION]->(m);
MERGE (n:Node {id: 4}) MERGE (m:Node {id: 6}) CREATE (n)-[:RELATION]->(m);
CALL tgn.train_and_eval(5) YIELD *
CALL tgn.get_results() YIELD epoch_num, batch_num, average_precision, batch_process_time, batch_type
RETURN epoch_num, batch_num, average_precision, batch_type, batch_process_time;
+--------------------+--------------------+--------------------+--------------------+--------------------+
| epoch_num | batch_num | average_precision | batch_type | batch_process_time |
+--------------------+--------------------+--------------------+--------------------+--------------------+
| 1 | 1 | 0.5 | "Train" | 0.05 |
| 1 | 2 | 0.42 | "Eval" | 0.02 |
| 2 | 1 | 0.83 | "Train" | 0.03 |
| 2 | 2 | 0.5 | "Train" | 0.04 |
| 2 | 3 | 0.5 | "Train" | 0.04 |
| 2 | 4 | 0.58 | "Train" | 0.04 |
| 2 | 5 | 0.83 | "Eval" | 0.02 |
| 3 | 1 | 0.5 | "Train" | 0.03 |
| 3 | 2 | 0.75 | "Train" | 0.03 |
| 3 | 3 | 0.83 | "Train" | 0.03 |
| 3 | 4 | 1 | "Train" | 0.04 |
| 3 | 5 | 0.83 | "Eval" | 0.02 |
| 4 | 1 | 0.5 | "Train" | 0.03 |
| 4 | 2 | 0.58 | "Train" | 0.03 |
| 4 | 3 | 1 | "Train" | 0.03 |
| 4 | 4 | 1 | "Train" | 0.04 |
| 4 | 5 | 1 | "Eval" | 0.02 |
| 5 | 1 | 0.83 | "Train" | 0.03 |
| 5 | 2 | 0.58 | "Train" | 0.03 |
| 5 | 3 | 1 | "Train" | 0.03 |
| 5 | 4 | 1 | "Train" | 0.03 |
| 5 | 5 | 0.83 | "Eval" | 0.02 |
| 6 | 1 | 0.58 | "Train" | 0.03 |
| 6 | 2 | 0.83 | "Train" | 0.03 |
| 6 | 3 | 1 | "Train" | 0.03 |
| 6 | 4 | 1 | "Train" | 0.03 |
| 6 | 5 | 1 | "Eval" | 0.01 |
+--------------------+--------------------+--------------------+--------------------+--------------------+