export_util
Module for exporting a graph database or query results in different formats. Currently, this module supports exporting database to a JSON file format and exporting query results in a CSV file format.
| Trait | Value |
|---|---|
| Module type | util |
| Implementation | Python |
| Parallelism | sequential |
Procedures
If you want to execute this algorithm on graph projections, subgraphs or portions of the graph, be sure to check out the guide on How to run a MAGE module on subgraphs.
json(path)
Input:
path: string➡ Path to the JSON file containing the exported graph database.
Usage:
The path you have to provide as procedure argument depends on how you started
Memgraph.
- Docker
- Linux
If you ran Memgraph with Docker, database will be exported to a JSON file inside
the Docker container. We recommend exporting the database to the JSON file
inside the /usr/lib/memgraph/query_modules directory.
You can call the procedure by running the following query:
CALL export_util.json(path);
where path is the path to the JSON file inside the
/usr/lib/memgraph/query_modules directory in the running Docker container (e.g.,
/usr/lib/memgraph/query_modules/export.json).
You can copy the exported CSV file to your local file system using the docker cp command.
To export database to a local JSON file create a new directory (for example,
export_folder) and run the following command to give the user memgraph the
necessary permissions:
sudo chown memgraph export_folder
Then, call the procedure by running the following query:
CALL export_util.json(path);
where path is the path to a local JSON file that will be created inside the
export_folder (e.g., /users/my_user/export_folder/export.json).
csv_query(query, file_path, stream)
Input:
query: string➡ A query from which the results will be saved to a CSV file.file_path: string (default="")➡ A path to the CSV file where the query results will be exported. Defaults to an empty string.stream: bool (default=False)➡ A value which determines whether a stream of query results in a CSV format will be returned.
Output:
file_path: string➡ A path to the CSV file where the query results are exported. Iffile_pathis not provided, the output will be an empty string.data: string➡ A stream of query results in a CSV format.
Usage:
The file_path you have to provide as procedure argument depends on how you started
Memgraph.
- Docker
- Linux
If you ran Memgraph with Docker, query results will be exported to a CSV file inside
the Docker container. We recommend exporting the database to the CSV file
inside the /usr/lib/memgraph/query_modules directory.
You can call the procedure by running the following query:
CALL export_util.csv_query(path);
where path is the path to a CSV file inside the
/usr/lib/memgraph/query_modules directory in the running Docker container (e.g.,
/usr/lib/memgraph/query_modules/export.csv).
You can copy the exported CSV file to your local file system using the docker cp command.
To export query results to a local CSV file create a new directory (for example,
export_folder) and run the following command to give the user memgraph the
necessary permissions:
sudo chown memgraph export_folder
Then, call the procedure by running the following query:
CALL export_util.csv_query(path);
where path is the path to a local CSV file that will be created inside the
export_folder (e.g., /users/my_user/export_folder/export.csv).
Example - Exporting database to a JSON file
- Step 1: Cypher load commands
- Step 2: Input graph
- Step 3: Running command
- Step 4: Results
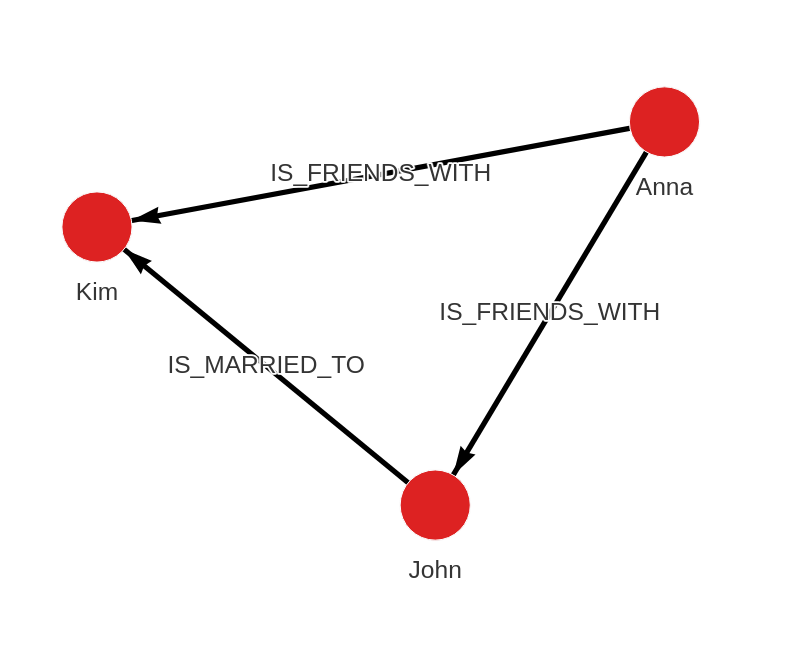
You can create a simple graph database by running the following queries:
CREATE (n:Person {name:"Anna"}), (m:Person {name:"John"}), (k:Person {name:"Kim"})
CREATE (n)-[:IS_FRIENDS_WITH]->(m), (n)-[:IS_FRIENDS_WITH]->(k), (m)-[:IS_MARRIED_TO]->(k);
The image below shows the above data as a graph:
If you're using Memgraph with Docker, the following Cypher query will
export the database to the export.json file in the
/usr/lib/memgraph/query_modules directory inside the running Docker container.
CALL export_util.json("/usr/lib/memgraph/query_modules/export.json");
If you're using Memgraph on Ubuntu, Debian, RPM package or WSL, the
following Cypher query will export the database to the export.json file in the
/users/my_user/export_folder.
CALL export_util.json("/users/my_user/export_folder/export.json");
The export.json file should be similar to the one below, except for the
id values that depend on the internal database id values:
[
{
"id": 6114,
"labels": [
"Person"
],
"properties": {
"name": "Anna"
},
"type": "node"
},
{
"id": 6115,
"labels": [
"Person"
],
"properties": {
"name": "John"
},
"type": "node"
},
{
"id": 6116,
"labels": [
"Person"
],
"properties": {
"name": "Kim"
},
"type": "node"
},
{
"end": 6115,
"id": 21120,
"label": "IS_FRIENDS_WITH",
"properties": {},
"start": 6114,
"type": "relationship"
},
{
"end": 6116,
"id": 21121,
"label": "IS_FRIENDS_WITH",
"properties": {},
"start": 6114,
"type": "relationship"
},
{
"end": 6116,
"id": 21122,
"label": "IS_MARRIED_TO",
"properties": {},
"start": 6115,
"type": "relationship"
}
]
Example - Exporting query results to a CSV file
- Step 1: Cypher load commands
- Step 2: Input graph
- Step 3: Running command
- Step 4: Results
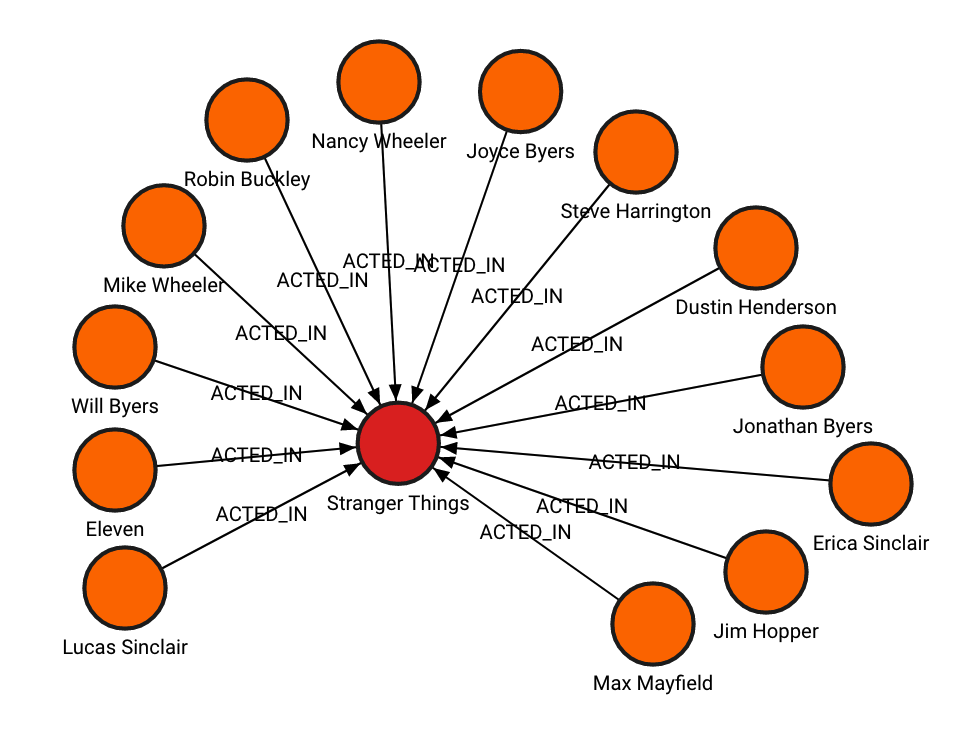
You can create a simple graph database by running the following queries:
CREATE (StrangerThings:TVShow {title:'Stranger Things', released:2016, program_creators:['Matt Duffer', 'Ross Duffer']})
CREATE (Eleven:Character {name:'Eleven', portrayed_by:'Millie Bobby Brown'})
CREATE (JoyceByers:Character {name:'Joyce Byers', portrayed_by:'Millie Bobby Brown'})
CREATE (JimHopper:Character {name:'Jim Hopper', portrayed_by:'Millie Bobby Brown'})
CREATE (MikeWheeler:Character {name:'Mike Wheeler', portrayed_by:'Finn Wolfhard'})
CREATE (DustinHenderson:Character {name:'Dustin Henderson', portrayed_by:'Gaten Matarazzo'})
CREATE (LucasSinclair:Character {name:'Lucas Sinclair', portrayed_by:'Caleb McLaughlin'})
CREATE (NancyWheeler:Character {name:'Nancy Wheeler', portrayed_by:'Natalia Dyer'})
CREATE (JonathanByers:Character {name:'Jonathan Byers', portrayed_by:'Charlie Heaton'})
CREATE (WillByers:Character {name:'Will Byers', portrayed_by:'Noah Schnapp'})
CREATE (SteveHarrington:Character {name:'Steve Harrington', portrayed_by:'Joe Keery'})
CREATE (MaxMayfield:Character {name:'Max Mayfield', portrayed_by:'Sadie Sink'})
CREATE (RobinBuckley:Character {name:'Robin Buckley', portrayed_by:'Maya Hawke'})
CREATE (EricaSinclair:Character {name:'Erica Sinclair', portrayed_by:'Priah Ferguson'})
CREATE
(Eleven)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JoyceByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JimHopper)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MikeWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(DustinHenderson)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(LucasSinclair)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(NancyWheeler)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(JonathanByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(WillByers)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(SteveHarrington)-[:ACTED_IN {seasons:[1, 2, 3, 4]}]->(StrangerThings),
(MaxMayfield)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings),
(RobinBuckley)-[:ACTED_IN {seasons:[3, 4]}]->(StrangerThings),
(EricaSinclair)-[:ACTED_IN {seasons:[2, 3, 4]}]->(StrangerThings);
The image below shows the above data as a graph:
If you're using Memgraph with Docker, the following Cypher query will
export the database to the export.csv file in the
/usr/lib/memgraph/query_modules directory inside the running Docker container.
WITH "MATCH path = (c:Character)-[:ACTED_IN]->(tvshow) RETURN c.name AS name, c.portrayed_by AS portrayed_by, tvshow.title AS title, tvshow.released AS released, tvshow.program_creators AS program_creators" AS query
CALL export_util.csv_query(query, "/usr/lib/memgraph/query_modules/export.csv", True)
YIELD file_path, data
RETURN file_path, data;
If you're using Memgraph on Ubuntu, Debian, RPM package or WSL, then the
following Cypher query will export the database to the export.csv file in the
/users/my_user/export_folder.
WITH "MATCH path = (c:Character)-[:ACTED_IN]->(tvshow) RETURN c.name AS name, c.portrayed_by AS portrayed_by, tvshow.title AS title, tvshow.released AS released, tvshow.program_creators AS program_creators" AS query
CALL export_util.csv_query(query, "/users/my_user/export_folder/export.csv", True)
YIELD file_path, data
RETURN file_path, data;
The output in the export.csv file looks like this:
name,portrayed_by,title,released,program_creators
Eleven,Millie Bobby Brown,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Joyce Byers,Millie Bobby Brown,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Jim Hopper,Millie Bobby Brown,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Mike Wheeler,Finn Wolfhard,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Dustin Henderson,Gaten Matarazzo,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Lucas Sinclair,Caleb McLaughlin,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Nancy Wheeler,Natalia Dyer,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Jonathan Byers,Charlie Heaton,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Will Byers,Noah Schnapp,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Steve Harrington,Joe Keery,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Max Mayfield,Sadie Sink,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Robin Buckley,Maya Hawke,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"
Erica Sinclair,Priah Ferguson,Stranger Things,2016,"['Matt Duffer', 'Ross Duffer']"