elasticsearch_synchronization
Elasticsearch is a text-processing platform that can be used to enhance the capabilities of a graph database like Memgraph. It offers many fine-grained features useful when working on a text that is impossible to develop in databases. Data residing in Elasticsearch and Memgraph should be synchronized because otherwise, the whole system could be in an inconsistent state. Such a feature can be added inside Memgraph by using triggers: every time a new entity is added (node or edge) it gets indexed to the Elasticsearch index.
The module supports the following features:
- creating Elasticsearch index from Memgraph clients using Cypher
- indexing all data inside Memgraph to Elasticsearch indexes
- managing Elasticsearch authentication in a secure way
- indexing entities (nodes and edges) as they are being inserted into the database without reindexing old data
- scanning and searching documents from Elasticsearch indexes using Query DSL
- reindexing existing documents from Elasticsearch
When using Elasticsearch synchronization modules:
- start Elasticsearch instance and securely store username, password, path to the certificate file and instance's URL
- connect to the instance by calling the
connectmethod - use the
create_indexmethod to create Elasticsearch indexes for nodes and edges - index all entities inside the database using the
index_dbmethod - check that documents were indexed correctly using the
scanorsearchmethod
Procedures
If you want to execute this algorithm on graph projections, subgraphs or portions of the graph, be sure to check out the guide on How to run a MAGE module on subgraphs.
The module for synchronizing Elasticsearch with Memgraph is organized as a stateful module where it is expected that the user performs a sequence of operations using a managed secure connection to Elasticsearch. The user can use indexes that already exist inside Elasticsearch but can also choose to create new ones with custom schema. Indexing can be performed in two ways:
- index all data residing inside the database
- incrementally index entities as they get inserted into the database by using triggers. Find more information about triggers in the reference guide or check how to set up triggers. Essentially, triggers offer a way of executing a specific procedure upon some event.
connect()
The connect() method is used for connecting to the Elasticsearch instance using Memgraph. It uses a basic authentication scheme with username, password and certificate.
Input:
elastic_url: str-> URL for connecting to the Elasticsearch instance.ca_certs: str-> Path to the certificate file.elastic_user: str-> The user trying to connect to Elasticsearch.elastic_password: str-> User's password for connecting to Elasticsearch.
Output:
connection_status: Dict[str, str]-> Connection info
An example of how you can use this method to connect to the Elasticsearch instance:
CALL elastic_search_serialization.connect("https://localhost:9200", "~/elasticsearch-8.4.3/config/certs/http_ca.crt", <ELASTIC_USER>, <ELASTIC_PASSWORD>) YIELD *;
create_index()
The method used for creating Elasticsearch indexes.
Input:
index_name: str-> Name of the index that needs to be created.schema_path: str-> Path to the schema from where the index will be loaded.schema_parameters: Dict[str, Any]number_of_shards: int-> Number of shards index will use.number_of_replicas: int-> Number of replicas index will use.analyzer: str-> Custom analyzer, which can be set to any legal Elasticsearch analyzer.
Output:
message_status: Dict[str, str]-> Output from the Elasticsearch instance whether the index was successfully created.
Use the following query to create Elasticsearch indexes:
CALL elastic_search_serialization.create_index("edge_index",
"edge_index_path_schema.json", {analyzer: "mem_analyzer", index_type: "edge"}) YIELD *;
index_db()
The method is used to serialize all vertices and relationships in MemgraphDB to Elasticsearch instance. By setting the thread_count, max_chunk_bytes, chunk_size, max_chunk_bytes and queue_size parameters, it is possible to get a good performance spot when indexing large quantities of documents.
Input
node_index: str-> The name of the node index. Can be used for both streaming and parallel bulk.edge_index: str-> The name of the edge index. Can be used for both streaming and parallel bulk.thread_count: int-> Size of the threadpool to use for the bulk requests.chunk_size: int-> The number of docs in one chunk sent to Elasticsearch (default: 500).max_chunk_bytes: int-> The maximum size of the request in bytes (default: 100MB).raise_on_error: bool-> RaiseBulkIndexErrorcontaining errors (as .errors) from the execution of the last chunk when some occur. By default, it's raised.raise_on_exception: bool-> IfFalsethen don’t propagate exceptions from call to bulk and just report the items that failed as failed.max_retries: int-> Maximum number of times a document will be retried when 429 is received, set to 0 (default) for no retries on 429.initial_backoff: float-> The number of seconds we should wait before the first retry. Any subsequent retries will be powers ofinitial_backoff * 2**retry_numbermax_backoff: float-> The maximum number of seconds a retry will wait.yield_ok: float-> If set toFalsewill skip successful documents in the output.queue_size: int-> Size of the task queue between the main thread (producing chunks to send) and the processing threads.
The method can be called in a following way:
CALL elastic_search_serialization.index_db("node_index", "edge_index", 5, 256, 104857600, True, False, 2, 2.0, 600.0, True, 2) YIELD *;
Output
number_of_nodes: int-> Number of indexed nodes.number_of_edges: int-> Number of indexed edges.
index()
The method is meant to be used in combination with triggers for incrementally indexing incoming data and it shouldn't be called by a user explicitly. Check out our docs where it is explained how Memgraph handles objects captured by various triggers.
Input
createdObjects: List[Dict[str, Object]]-> Objects that are captured by a create trigger.node_index: str-> The name of the node index. Can be used for both streaming and parallel bulk.edge_index: str-> The name of the edge index. Can be used for both streaming and parallel bulk.thread_count: int-> Size of the threadpool to use for the bulk requests.chunk_size: int-> The number of docs in one chunk sent to Elasticsearch (default: 500).max_chunk_bytes: int-> The maximum size of the request in bytes (default: 100MB).raise_on_error: bool-> RaiseBulkIndexErrorcontaining errors (as .errors) from the execution of the last chunk when some occur. By default, it's raised.raise_on_exception: bool-> IfFalsethen don’t propagate exceptions from call to bulk and just report the items that failed as failed.max_retries: int-> Maximum number of times a document will be retried when 429 is received, set to 0 (default) for no retries on 429.initial_backoff: float-> The number of seconds we should wait before the first retry. Any subsequent retries will be powers ofinitial_backoff * 2**retry_numbermax_backoff: float-> The maximum number of seconds a retry will wait.yield_ok: float-> If set toFalsewill skip successful documents in the output.queue_size: int-> Size of the task queue between the main thread (producing chunks to send) and the processing threads.
The method can be used in a following way:
CREATE TRIGGER elastic_search_create
ON CREATE AFTER COMMIT EXECUTE
CALL elastic_search_serialization.index(createdObjects, "docs_nodes", "docs_edges") YIELD * RETURN *;
Output
number_of_nodes: int-> Number of indexed nodes.number_of_edges: int-> Number of indexed edges.
Input
node_index: str-> The name of the node index. Can be used for both streaming and parallel bulk.edge_index: str-> The name of the edge index. Can be used for both streaming and parallel bulk.chunk_size: int-> The number of docs in one chunk sent to Elasticsearch (default: 500).max_chunk_bytes: int-> The maximum size of the request in bytes (default: 100MB).raise_on_error: bool-> RaiseBulkIndexErrorcontaining errors (as .errors) from the execution of the last chunk when some occur. By default, it's raised.raise_on_exception: bool-> IfFalsethen don’t propagate exceptions from call to bulk and just report the items that failed as failed.max_retries: int-> Maximum number of times a document will be retried when 429 is received, set to 0 (default) for no retries on 429.initial_backoff: float-> The number of seconds we should wait before the first retry. Any subsequent retries will be powers ofinitial_backoff * 2**retry_numbermax_backoff: float-> The maximum number of seconds a retry will wait.yield_ok: float-> If set toFalsewill skip successful documents in the output.thread_count: int-> Size of the threadpool to use for the bulk requests.queue_size: int-> Size of the task queue between the main thread (producing chunks to send) and the processing threads.
The method can be called in a following way:
CALL elastic_search_serialization.index_db("node_index", "edge_index", 5, 256, 104857600, True, False, 2, 2.0, 600.0, True, 2) YIELD *;
Output
number_of_nodes: int-> Number of indexed nodes.number_of_edges: int-> Number of indexed edges.
reindex()
Reindex all documents that satisfy a given query from one index to another, potentially (if target_client is specified) on a different cluster. If you don’t specify the query you will reindex all the documents.
Input
updatatedObjects: List[Dict[str, Any]]-> List of all objects that were updated and then sent as arguments to this method with the help of the update trigger.source_index: Union[str, List[str]])-> Identifies source index (or more of them) from where documents need to be indexed.target_index: str-> Identifies target index to where documents need to be indexed.query: str-> Query written as JSON.chunk_size: int-> Number of docs in one chunk sent to Elasticsearch (default: 500).scroll: str-> Specifies how long a consistent view of the index should be maintained for scrolled search.op_type: Optional[str])-> Explicit operation type. Defaults to_index. Data streams must be set tocreate. If not specified, will auto-detect if target_index is a data stream.
Output
response: str-> Number of documents matched by a query in thesource_index.
To reindex all documents from the source_index to the destination_index, use the following query:
CALL elastic_search_serialization.reindex("source_index", "destination_index", "{\"query\": {\"match_all\": {}}} ") YIELD * RETURN *;
scan()
Fetches documents from the index specified by the index_name matched by the query. Supports pagination.
Input
index_name: str-> Name of the index.query: str-> Query written as JSON.scroll: int-> Specifies how long a consistent view of the index should be maintained for scrolled search.raise_on_error: bool-> Raises an exception (ScanError) if an error is encountered (some shards fail to execute). By default, it's raised.preserve_order: bool-> By defaultscan()does not return results in any pre-determined order. To have a standard order in the returned documents (either by score or explicit sort definition) when scrolling, setpreserve_order=True. Don’t set the search_type to scan - this will cause the scroll to paginate with preserving the order. Note that this can be an extremely expensive operation and can easily lead to unpredictable results, use it with caution.size: int-> Size (per shard) of the batch sent at each iteration.from: int-> Starting document offset. By default, you cannot page through more than 10,000 hits using thefromand size parameters. To page through more hits, use thesearch_afterparameter.request_timeout: mgp.Nullable[float]-> Explicit timeout for each call to scan.clear_scroll: bool-> Explicitly calls delete on the scroll id via the clear scroll API at the end of the method on completion or error, defaults to true.
Output
documents: List[Dict[str, str]]-> List of all items matched by the specific query.
Below is an example scan query that makes use of all parameters:
CALL elastic_search_serialization.scan("edge_index", "{\"query\": {\"match_all\": {}}}", "5m", false, false, 100, 0, 2.0, False) YIELD *;
search()
Searches for all documents by specifying query and index. It is the preferred method to be used before the scan() method because of the possibility to use aggregations.
Input
index_name: str-> A name of the index.query: str-> Query written as JSON.size: int-> Size (per shard) of the batch sent at each iteration.from_: int-> Starting document offset. By default, you cannot page through more than 10,000 hits using thefromand size parameters. To page through more hits, use thesearch_afterparameter.aggregations: Optional[Mapping[str, Mapping[str, Any]]]-> Check out the (docs)[https://elasticsearch-py.readthedocs.io/en/v8.5.3/api.html#elasticsearch.Elasticsearch.search]aggs: Optional[Mapping[str, Mapping[str, Any]]]-> Check out the (docs)[https://elasticsearch-py.readthedocs.io/en/v8.5.3/api.html#elasticsearch.Elasticsearch.search]
Output
documents: Dict[str, str]→ Returns results matching a query.
A query without aggregations that represents how the search method could be used:
CALL elastic_search_serialization.search("node_index", "{\"match_all\": {}}", 1000, 0) YIELD *;
Example
Example shows all module's features, from connecting to the Elasticsearch instance up to the synchronizing Memgraph and Elasticsearch using triggers.
- Step 1: Connect and populate
- Step 2: Create indexes
- Step 3: Index database
- Step 4: Scan
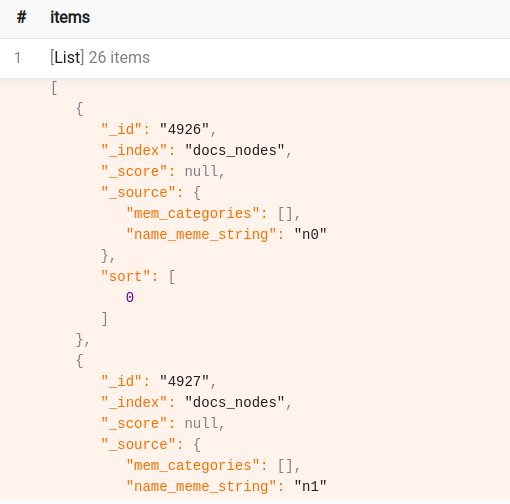
- Step 5: Scan results
- Step 6: Create trigger
- Step 7: Insert node and edge
- Step 8: Search
- Step 9: Search results
CALL elastic_search_serialization.connect("https://localhost:9200", "http_ca.crt", "<ELASTIC_USER>","<ELASTIC_PASSWORD>") YIELD *;
CREATE (n0 {name: "n0"}), (n1 {name: "n1"}), (n2 {name: "n2"}), (n3 {name: "n3"}), (n4 {name: "n4"}), (n5 {name: "n5"}), (n6 {name: "n6"});
CREATE (n1)-[r1:RELATED]->(n2);
CREATE (n1)-[r2:RELATED]->(n3);
CREATE (n1)-[r3:RELATED]->(n3);
CREATE (n2)-[r4:RELATED]->(n1);
CREATE (n2)-[r5:RELATED]->(n5);
CREATE (n2)-[r6:RELATED]->(n3);
CREATE (n3)-[r7:RELATED]->(n6);
CREATE (n3)-[r8:RELATED]->(n1);
CREATE (n1)-[r9:RELATED]->(n4);
CALL elastic_search_serialization.create_index("docs_nodes", "node_index_path_schema.json",
{analyzer: "mem_analyzer", index_type: "vertex"}) YIELD *;
CALL elastic_search_serialization.create_index("docs_edges", "edge_index_path_schema.json", {analyzer: "mem_analyzer", index_type: "edge"}) YIELD *;
CALL elastic_search_serialization.index_db("docs_nodes", "docs_edges", 4) YIELD *;
CALL elastic_search_serialization.scan("docs_nodes", "{\"query\": {\"match_all\": {}}}", "5m", false, false, 100, 0, 2.0, False) YIELD *;
CREATE TRIGGER elastic_search_create
ON CREATE AFTER COMMIT EXECUTE
CALL elastic_search_serialization.index(createdObjects, "docs_nodes", "docs_edges") YIELD * RETURN *;
CREATE (n7 {name: "n7"});
MATCH (n6 {name: "n6"}), (n7 {name: "n7"})
CREATE (n6)-[:NEW_CONNECTION {edge_property: "docs"}]->(n7);
CALL elastic_search_serialization.search("docs_nodes", "{\"match_all\": {}}", 1000, 0) YIELD *;
