WHERE clause
WHERE isn't usually considered a standalone clause but rather a part of the
MATCH, OPTIONAL MATCH and WITH clauses.
When used next to the WITH clause, the WHERE clause only filters the
results, while when used with MATCH and OPTIONAL MATCH it adds constraints
to the described patterns.
WHERE should be used directly after MATCH or OPTIONAL MATCH clauses in
order to avoid problems with performance or results.
- Basic usage
1.1. Boolean Operators
1.2. Inequality Operators Operators
1.3. Filter with node labels
1.4. Filter with node properties
1.5. Filter with relationship properties
1.6. Check if property is not null
1.7. Filter with pattern expressions - String matching
- Regular Expressions
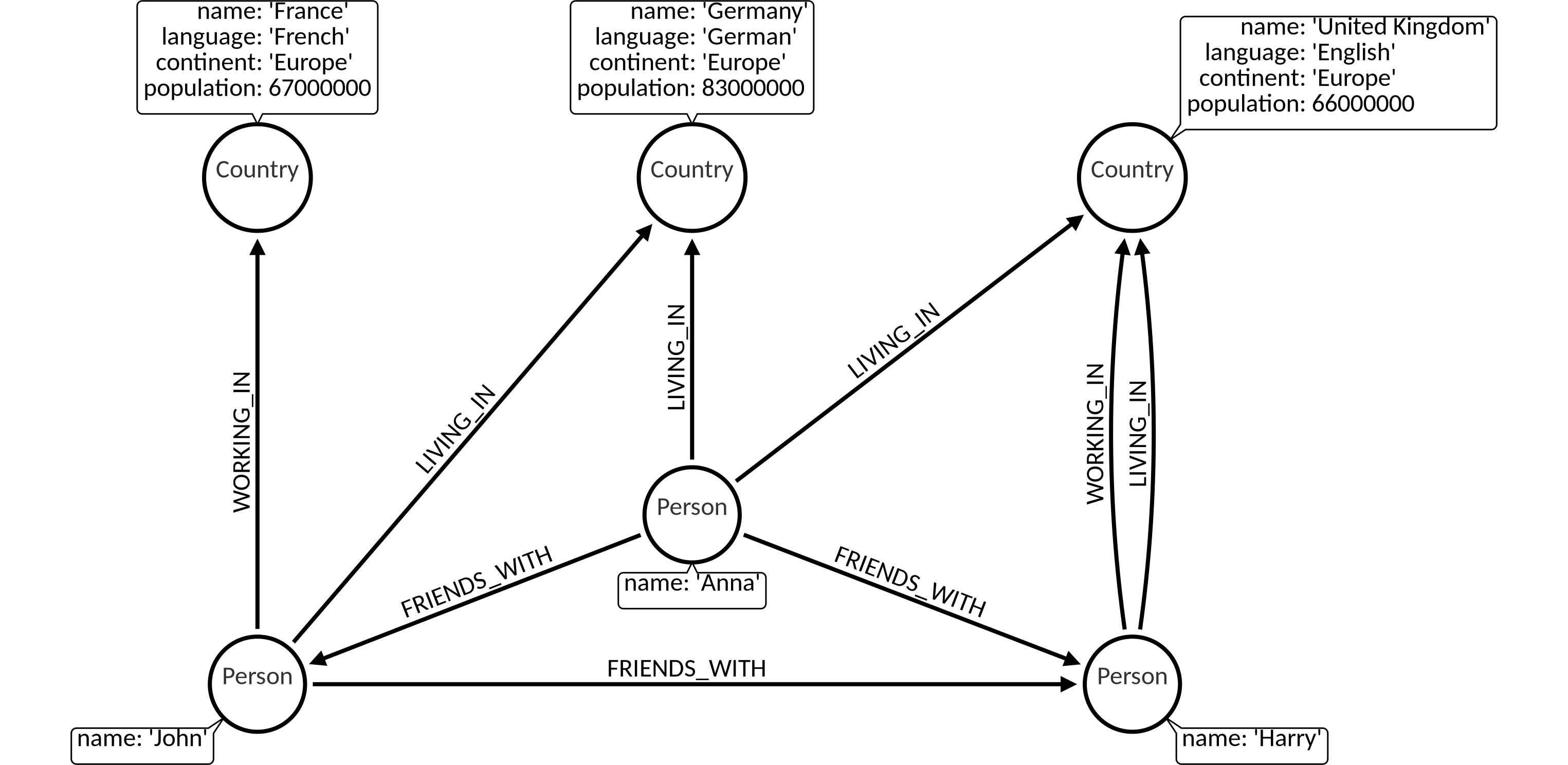
Dataset
The following examples are executed with this dataset. You can create this dataset locally by executing the queries at the end of the page: Dataset queries.
1. Basic Usage
1.1. Boolean Operators
Standard boolean operators like NOT, AND, OR and XOR can be used:
MATCH (c:Country)
WHERE c.language = 'English' AND c.continent = 'Europe'
RETURN c.name;
Output:
+----------------+
| c.name |
+----------------+
| United Kingdom |
+----------------+
1.2. Inequality Operators Operators
Standard inequality operators like <, <=, > and >= can be used:
MATCH (c:Country)
WHERE (c.population > 80000000)
RETURN c.name;
Output:
+---------+
| c.name |
+---------+
| Germany |
+---------+
1.3. Filter with node labels
Nodes can be filtered by their label using the WHERE clause instead of specifying it directly in the MATCH clause:
MATCH (c)
WHERE c:Country
RETURN c.name;
Output:
+----------------+
| c.name |
+----------------+
| Germany |
| France |
| United Kingdom |
+----------------+
1.4. Filter with node properties
Just as labels, node properties can be used in the WHERE clause to filter nodes:
MATCH (c:Country)
WHERE c.population < 70000000
RETURN c.name;
Output:
+----------------+
| c.name |
+----------------+
| France |
| United Kingdom |
+----------------+
1.5. Filter with relationship properties
Just as with node properties, relationship properties can be used as filters:
MATCH (:Country {name: 'United Kingdom'})-[r]-(p)
WHERE r.date_of_start = 2014
RETURN p;
Output:
+---------------------------+
| p |
+---------------------------+
| (:Person {name: "Harry"}) |
| (:Person {name: "Anna"}) |
+---------------------------+
1.6. Check if property is not null
To check if a node or relationship property exists use the IS NOT NULL option:
MATCH (c:Country)
WHERE c.name = 'United Kingdom' AND c.population IS NOT NULL
RETURN c.name, c.population;
Output:
+----------------+----------------+
| c.name | c.population |
+----------------+----------------+
| United Kingdom | 66000000 |
+----------------+----------------+
1.7. Filter with pattern expressions
Currently, we support pattern expression filters with the exists(pattern) function, which can perform filters based on
neighboring entities:
MATCH (p:Person)
WHERE exists((p)-[:LIVING_IN]->(:Country {name: 'Germany'}))
RETURN p.name
ORDER BY p.name;
Output:
+----------------+
| c.name |
+----------------+
| Anna |
| John |
+----------------+
2. String matching
Apart from comparison and concatenation operators Cypher provides special string operators for easier matching of substrings:
| Operator | Description |
|---|---|
a STARTS WITH b | Returns true if the prefix of string a is equal to string b. |
a ENDS WITH b | Returns true if the suffix of string a is equal to string b. |
a CONTAINS b | Returns true if some substring of string a is equal to string b. |
MATCH (c:Country)
WHERE c.name STARTS WITH 'G' AND NOT c.name CONTAINS 't'
RETURN c.name;
Output:
+---------+
| c.name |
+---------+
| Germany |
+---------+
3. Regular expressions
Inside WHERE clause, you can use regular expressions for text filtering. To
use a regular expression, you need to use the =~ operator.
For example, finding all Person nodes which have a name ending with a:
MATCH (n:Person) WHERE n.name =~ ".*a$" RETURN n;
Output:
+--------------------------+
| n |
+--------------------------+
| (:Person {name: "Anna"}) |
+--------------------------+
The regular expression syntax is based on the modified ECMAScript regular expression grammar. The ECMAScript grammar can be found here, while the modifications are described in this document.
Dataset queries
We encourage you to try out the examples by yourself. You can get our dataset locally by executing the following query block.
MATCH (n) DETACH DELETE n;
CREATE (c1:Country {name: 'Germany', language: 'German', continent: 'Europe', population: 83000000});
CREATE (c2:Country {name: 'France', language: 'French', continent: 'Europe', population: 67000000});
CREATE (c3:Country {name: 'United Kingdom', language: 'English', continent: 'Europe', population: 66000000});
MATCH (c1),(c2)
WHERE c1.name= 'Germany' AND c2.name = 'France'
CREATE (c2)<-[:WORKING_IN {date_of_start: 2014}]-(p:Person {name: 'John'})-[:LIVING_IN {date_of_start: 2014}]->(c1);
MATCH (c)
WHERE c.name= 'United Kingdom'
CREATE (c)<-[:WORKING_IN {date_of_start: 2014}]-(p:Person {name: 'Harry'})-[:LIVING_IN {date_of_start: 2013}]->(c);
MATCH (p1),(p2)
WHERE p1.name = 'John' AND p2.name = 'Harry'
CREATE (p1)-[:FRIENDS_WITH {date_of_start: 2011}]->(p2);
MATCH (p1),(p2)
WHERE p1.name = 'John' AND p2.name = 'Harry'
CREATE (p1)<-[:FRIENDS_WITH {date_of_start: 2012}]-(:Person {name: 'Anna'})-[:FRIENDS_WITH {date_of_start: 2014}]->(p2);
MATCH (p),(c1),(c2)
WHERE p.name = 'Anna' AND c1.name = 'United Kingdom' AND c2.name = 'Germany'
CREATE (c2)<-[:LIVING_IN {date_of_start: 2014}]-(p)-[:LIVING_IN {date_of_start: 2014}]->(c1);
MATCH (n)-[r]->(m) RETURN n,r,m;