- What is Elasticsearch?
- What’s new in 8.10
- Set up Elasticsearch
- Installing Elasticsearch
- Run Elasticsearch locally
- Configuring Elasticsearch
- Important Elasticsearch configuration
- Secure settings
- Auditing settings
- Circuit breaker settings
- Cluster-level shard allocation and routing settings
- Miscellaneous cluster settings
- Cross-cluster replication settings
- Discovery and cluster formation settings
- Field data cache settings
- Health Diagnostic settings
- Index lifecycle management settings
- Data stream lifecycle settings
- Index management settings
- Index recovery settings
- Indexing buffer settings
- License settings
- Local gateway settings
- Logging
- Machine learning settings
- Monitoring settings
- Node
- Networking
- Node query cache settings
- Search settings
- Security settings
- Shard request cache settings
- Snapshot and restore settings
- Transforms settings
- Thread pools
- Watcher settings
- Advanced configuration
- Important system configuration
- Bootstrap Checks
- Heap size check
- File descriptor check
- Memory lock check
- Maximum number of threads check
- Max file size check
- Maximum size virtual memory check
- Maximum map count check
- Client JVM check
- Use serial collector check
- System call filter check
- OnError and OnOutOfMemoryError checks
- Early-access check
- G1GC check
- All permission check
- Discovery configuration check
- Bootstrap Checks for X-Pack
- Starting Elasticsearch
- Stopping Elasticsearch
- Discovery and cluster formation
- Add and remove nodes in your cluster
- Full-cluster restart and rolling restart
- Remote clusters
- Plugins
- Upgrade Elasticsearch
- Index modules
- Mapping
- Text analysis
- Overview
- Concepts
- Configure text analysis
- Built-in analyzer reference
- Tokenizer reference
- Token filter reference
- Apostrophe
- ASCII folding
- CJK bigram
- CJK width
- Classic
- Common grams
- Conditional
- Decimal digit
- Delimited payload
- Dictionary decompounder
- Edge n-gram
- Elision
- Fingerprint
- Flatten graph
- Hunspell
- Hyphenation decompounder
- Keep types
- Keep words
- Keyword marker
- Keyword repeat
- KStem
- Length
- Limit token count
- Lowercase
- MinHash
- Multiplexer
- N-gram
- Normalization
- Pattern capture
- Pattern replace
- Phonetic
- Porter stem
- Predicate script
- Remove duplicates
- Reverse
- Shingle
- Snowball
- Stemmer
- Stemmer override
- Stop
- Synonym
- Synonym graph
- Trim
- Truncate
- Unique
- Uppercase
- Word delimiter
- Word delimiter graph
- Character filters reference
- Normalizers
- Index templates
- Data streams
- Ingest pipelines
- Example: Parse logs
- Enrich your data
- Processor reference
- Append
- Attachment
- Bytes
- Circle
- Community ID
- Convert
- CSV
- Date
- Date index name
- Dissect
- Dot expander
- Drop
- Enrich
- Fail
- Fingerprint
- Foreach
- Geo-grid
- GeoIP
- Grok
- Gsub
- HTML strip
- Inference
- Join
- JSON
- KV
- Lowercase
- Network direction
- Pipeline
- Redact
- Registered domain
- Remove
- Rename
- Reroute
- Script
- Set
- Set security user
- Sort
- Split
- Trim
- Uppercase
- URL decode
- URI parts
- User agent
- Aliases
- Search your data
- Collapse search results
- Filter search results
- Highlighting
- Long-running searches
- Near real-time search
- Paginate search results
- Retrieve inner hits
- Retrieve selected fields
- Search across clusters
- Search multiple data streams and indices
- Search shard routing
- Search templates
- Search with synonyms
- Sort search results
- kNN search
- Semantic search
- Searching with query rules
- Query DSL
- Aggregations
- Bucket aggregations
- Adjacency matrix
- Auto-interval date histogram
- Categorize text
- Children
- Composite
- Date histogram
- Date range
- Diversified sampler
- Filter
- Filters
- Frequent item sets
- Geo-distance
- Geohash grid
- Geohex grid
- Geotile grid
- Global
- Histogram
- IP prefix
- IP range
- Missing
- Multi Terms
- Nested
- Parent
- Random sampler
- Range
- Rare terms
- Reverse nested
- Sampler
- Significant terms
- Significant text
- Terms
- Time series
- Variable width histogram
- Subtleties of bucketing range fields
- Metrics aggregations
- Pipeline aggregations
- Average bucket
- Bucket script
- Bucket count K-S test
- Bucket correlation
- Bucket selector
- Bucket sort
- Change point
- Cumulative cardinality
- Cumulative sum
- Derivative
- Extended stats bucket
- Inference bucket
- Max bucket
- Min bucket
- Moving function
- Moving percentiles
- Normalize
- Percentiles bucket
- Serial differencing
- Stats bucket
- Sum bucket
- Bucket aggregations
- Geospatial analysis
- EQL
- ES|QL
- Syntax reference
- Source commands
- Processing commands
- Functions
ABSACOSASINATANATAN2AUTO_BUCKETCASECEILCIDR_MATCHCOALESCECONCATCOSCOSHDATE_EXTRACTDATE_FORMATDATE_PARSEDATE_TRUNCEFLOORGREATESTIS_FINITEIS_INFINITEIS_NANLEASTLEFTLENGTHLOG10LTRIMMV_AVGMV_CONCATMV_COUNTMV_DEDUPEMV_MAXMV_MEDIANMV_MINMV_SUMNOWPIPOWRIGHTROUNDRTRIMSINSINHSPLITSQRTSTARTS_WITHSUBSTRINGTANTANHTAUTO_BOOLEANTO_DATETIMETO_DEGREESTO_DOUBLETO_INTEGERTO_IPTO_LONGTO_RADIANSTO_STRINGTO_UNSIGNED_LONGTO_VERSIONTRIM
- Aggregation functions
- Multivalued fields
- Metadata fields
- Task management
- SQL
- Overview
- Getting Started with SQL
- Conventions and Terminology
- Security
- SQL REST API
- SQL Translate API
- SQL CLI
- SQL JDBC
- SQL ODBC
- SQL Client Applications
- SQL Language
- Functions and Operators
- Comparison Operators
- Logical Operators
- Math Operators
- Cast Operators
- LIKE and RLIKE Operators
- Aggregate Functions
- Grouping Functions
- Date/Time and Interval Functions and Operators
- Full-Text Search Functions
- Mathematical Functions
- String Functions
- Type Conversion Functions
- Geo Functions
- Conditional Functions And Expressions
- System Functions
- Reserved keywords
- SQL Limitations
- Scripting
- Data management
- ILM: Manage the index lifecycle
- Tutorial: Customize built-in policies
- Tutorial: Automate rollover
- Index management in Kibana
- Overview
- Concepts
- Index lifecycle actions
- Configure a lifecycle policy
- Migrate index allocation filters to node roles
- Troubleshooting index lifecycle management errors
- Start and stop index lifecycle management
- Manage existing indices
- Skip rollover
- Restore a managed data stream or index
- Data tiers
- Autoscaling
- Monitor a cluster
- Roll up or transform your data
- Set up a cluster for high availability
- Snapshot and restore
- Secure the Elastic Stack
- Elasticsearch security principles
- Start the Elastic Stack with security enabled automatically
- Manually configure security
- Updating node security certificates
- User authentication
- Built-in users
- Service accounts
- Internal users
- Token-based authentication services
- User profiles
- Realms
- Realm chains
- Security domains
- Active Directory user authentication
- File-based user authentication
- LDAP user authentication
- Native user authentication
- OpenID Connect authentication
- PKI user authentication
- SAML authentication
- Kerberos authentication
- JWT authentication
- Integrating with other authentication systems
- Enabling anonymous access
- Looking up users without authentication
- Controlling the user cache
- Configuring SAML single-sign-on on the Elastic Stack
- Configuring single sign-on to the Elastic Stack using OpenID Connect
- User authorization
- Built-in roles
- Defining roles
- Role restriction
- Security privileges
- Document level security
- Field level security
- Granting privileges for data streams and aliases
- Mapping users and groups to roles
- Setting up field and document level security
- Submitting requests on behalf of other users
- Configuring authorization delegation
- Customizing roles and authorization
- Enable audit logging
- Restricting connections with IP filtering
- Securing clients and integrations
- Operator privileges
- Troubleshooting
- Some settings are not returned via the nodes settings API
- Authorization exceptions
- Users command fails due to extra arguments
- Users are frequently locked out of Active Directory
- Certificate verification fails for curl on Mac
- SSLHandshakeException causes connections to fail
- Common SSL/TLS exceptions
- Common Kerberos exceptions
- Common SAML issues
- Internal Server Error in Kibana
- Setup-passwords command fails due to connection failure
- Failures due to relocation of the configuration files
- Limitations
- Watcher
- Command line tools
- elasticsearch-certgen
- elasticsearch-certutil
- elasticsearch-create-enrollment-token
- elasticsearch-croneval
- elasticsearch-keystore
- elasticsearch-node
- elasticsearch-reconfigure-node
- elasticsearch-reset-password
- elasticsearch-saml-metadata
- elasticsearch-service-tokens
- elasticsearch-setup-passwords
- elasticsearch-shard
- elasticsearch-syskeygen
- elasticsearch-users
- How to
- Troubleshooting
- Fix common cluster issues
- Diagnose unassigned shards
- Add a missing tier to the system
- Allow Elasticsearch to allocate the data in the system
- Allow Elasticsearch to allocate the index
- Indices mix index allocation filters with data tiers node roles to move through data tiers
- Not enough nodes to allocate all shard replicas
- Total number of shards for an index on a single node exceeded
- Total number of shards per node has been reached
- Troubleshooting corruption
- Fix data nodes out of disk
- Fix master nodes out of disk
- Fix other role nodes out of disk
- Start index lifecycle management
- Start Snapshot Lifecycle Management
- Restore from snapshot
- Multiple deployments writing to the same snapshot repository
- Addressing repeated snapshot policy failures
- Troubleshooting an unstable cluster
- Troubleshooting discovery
- Troubleshooting monitoring
- Troubleshooting transforms
- Troubleshooting Watcher
- Troubleshooting searches
- Troubleshooting shards capacity health issues
- REST APIs
- API conventions
- Common options
- REST API compatibility
- Autoscaling APIs
- Behavioral Analytics APIs
- Compact and aligned text (CAT) APIs
- cat aliases
- cat allocation
- cat anomaly detectors
- cat component templates
- cat count
- cat data frame analytics
- cat datafeeds
- cat fielddata
- cat health
- cat indices
- cat master
- cat nodeattrs
- cat nodes
- cat pending tasks
- cat plugins
- cat recovery
- cat repositories
- cat segments
- cat shards
- cat snapshots
- cat task management
- cat templates
- cat thread pool
- cat trained model
- cat transforms
- Cluster APIs
- Cluster allocation explain
- Cluster get settings
- Cluster health
- Health
- Cluster reroute
- Cluster state
- Cluster stats
- Cluster update settings
- Nodes feature usage
- Nodes hot threads
- Nodes info
- Prevalidate node removal
- Nodes reload secure settings
- Nodes stats
- Cluster Info
- Pending cluster tasks
- Remote cluster info
- Task management
- Voting configuration exclusions
- Create or update desired nodes
- Get desired nodes
- Delete desired nodes
- Get desired balance
- Reset desired balance
- Cross-cluster replication APIs
- Data stream APIs
- Document APIs
- Enrich APIs
- EQL APIs
- Features APIs
- Fleet APIs
- Find structure API
- Graph explore API
- Index APIs
- Alias exists
- Aliases
- Analyze
- Analyze index disk usage
- Clear cache
- Clone index
- Close index
- Create index
- Create or update alias
- Create or update component template
- Create or update index template
- Create or update index template (legacy)
- Delete component template
- Delete dangling index
- Delete alias
- Delete index
- Delete index template
- Delete index template (legacy)
- Exists
- Field usage stats
- Flush
- Force merge
- Get alias
- Get component template
- Get field mapping
- Get index
- Get index settings
- Get index template
- Get index template (legacy)
- Get mapping
- Import dangling index
- Index recovery
- Index segments
- Index shard stores
- Index stats
- Index template exists (legacy)
- List dangling indices
- Open index
- Refresh
- Resolve index
- Rollover
- Shrink index
- Simulate index
- Simulate template
- Split index
- Unfreeze index
- Update index settings
- Update mapping
- Index lifecycle management APIs
- Create or update lifecycle policy
- Get policy
- Delete policy
- Move to step
- Remove policy
- Retry policy
- Get index lifecycle management status
- Explain lifecycle
- Start index lifecycle management
- Stop index lifecycle management
- Migrate indices, ILM policies, and legacy, composable and component templates to data tiers routing
- Ingest APIs
- Info API
- Licensing APIs
- Logstash APIs
- Machine learning APIs
- Machine learning anomaly detection APIs
- Add events to calendar
- Add jobs to calendar
- Close jobs
- Create jobs
- Create calendars
- Create datafeeds
- Create filters
- Delete calendars
- Delete datafeeds
- Delete events from calendar
- Delete filters
- Delete forecasts
- Delete jobs
- Delete jobs from calendar
- Delete model snapshots
- Delete expired data
- Estimate model memory
- Flush jobs
- Forecast jobs
- Get buckets
- Get calendars
- Get categories
- Get datafeeds
- Get datafeed statistics
- Get influencers
- Get jobs
- Get job statistics
- Get model snapshots
- Get model snapshot upgrade statistics
- Get overall buckets
- Get scheduled events
- Get filters
- Get records
- Open jobs
- Post data to jobs
- Preview datafeeds
- Reset jobs
- Revert model snapshots
- Start datafeeds
- Stop datafeeds
- Update datafeeds
- Update filters
- Update jobs
- Update model snapshots
- Upgrade model snapshots
- Machine learning data frame analytics APIs
- Create data frame analytics jobs
- Delete data frame analytics jobs
- Evaluate data frame analytics
- Explain data frame analytics
- Get data frame analytics jobs
- Get data frame analytics jobs stats
- Preview data frame analytics
- Start data frame analytics jobs
- Stop data frame analytics jobs
- Update data frame analytics jobs
- Machine learning trained model APIs
- Clear trained model deployment cache
- Create or update trained model aliases
- Create part of a trained model
- Create trained models
- Create trained model vocabulary
- Delete trained model aliases
- Delete trained models
- Get trained models
- Get trained models stats
- Infer trained model
- Start trained model deployment
- Stop trained model deployment
- Update trained model deployment
- Migration APIs
- Node lifecycle APIs
- Query rules APIs
- Reload search analyzers API
- Repositories metering APIs
- Rollup APIs
- Script APIs
- Search APIs
- Search Application APIs
- Searchable snapshots APIs
- Security APIs
- Authenticate
- Change passwords
- Clear cache
- Clear roles cache
- Clear privileges cache
- Clear API key cache
- Clear service account token caches
- Create API keys
- Create or update application privileges
- Create or update role mappings
- Create or update roles
- Create or update users
- Create service account tokens
- Delegate PKI authentication
- Delete application privileges
- Delete role mappings
- Delete roles
- Delete service account token
- Delete users
- Disable users
- Enable users
- Enroll Kibana
- Enroll node
- Get API key information
- Get application privileges
- Get builtin privileges
- Get role mappings
- Get roles
- Get service accounts
- Get service account credentials
- Get token
- Get user privileges
- Get users
- Grant API keys
- Has privileges
- Invalidate API key
- Invalidate token
- OpenID Connect prepare authentication
- OpenID Connect authenticate
- OpenID Connect logout
- Query API key information
- Update API key
- Bulk update API keys
- SAML prepare authentication
- SAML authenticate
- SAML logout
- SAML invalidate
- SAML complete logout
- SAML service provider metadata
- SSL certificate
- Activate user profile
- Disable user profile
- Enable user profile
- Get user profiles
- Suggest user profile
- Update user profile data
- Has privileges user profile
- Create Cross-Cluster API key
- Update Cross-Cluster API key
- Snapshot and restore APIs
- Snapshot lifecycle management APIs
- SQL APIs
- Synonyms APIs
- Transform APIs
- Usage API
- Watcher APIs
- Definitions
- Migration guide
- Release notes
- Elasticsearch version 8.11.0
- Elasticsearch version 8.10.0
- Elasticsearch version 8.9.2
- Elasticsearch version 8.9.1
- Elasticsearch version 8.9.0
- Elasticsearch version 8.8.2
- Elasticsearch version 8.8.1
- Elasticsearch version 8.8.0
- Elasticsearch version 8.7.1
- Elasticsearch version 8.7.0
- Elasticsearch version 8.6.2
- Elasticsearch version 8.6.1
- Elasticsearch version 8.6.0
- Elasticsearch version 8.5.3
- Elasticsearch version 8.5.2
- Elasticsearch version 8.5.1
- Elasticsearch version 8.5.0
- Elasticsearch version 8.4.3
- Elasticsearch version 8.4.2
- Elasticsearch version 8.4.1
- Elasticsearch version 8.4.0
- Elasticsearch version 8.3.3
- Elasticsearch version 8.3.2
- Elasticsearch version 8.3.1
- Elasticsearch version 8.3.0
- Elasticsearch version 8.2.3
- Elasticsearch version 8.2.2
- Elasticsearch version 8.2.1
- Elasticsearch version 8.2.0
- Elasticsearch version 8.1.3
- Elasticsearch version 8.1.2
- Elasticsearch version 8.1.1
- Elasticsearch version 8.1.0
- Elasticsearch version 8.0.1
- Elasticsearch version 8.0.0
- Elasticsearch version 8.0.0-rc2
- Elasticsearch version 8.0.0-rc1
- Elasticsearch version 8.0.0-beta1
- Elasticsearch version 8.0.0-alpha2
- Elasticsearch version 8.0.0-alpha1
- Dependencies and versions
Geo-line aggregationedit
The geo_line aggregation aggregates all geo_point values within a bucket into a LineString ordered
by the chosen sort field. This sort can be a date field, for example. The bucket returned is a valid
GeoJSON Feature representing the line geometry.
PUT test { "mappings": { "properties": { "my_location": { "type": "geo_point" }, "group": { "type": "keyword" }, "@timestamp": { "type": "date" } } } } POST /test/_bulk?refresh {"index":{}} {"my_location": {"lat":52.373184, "lon":4.889187}, "@timestamp": "2023-01-02T09:00:00Z"} {"index":{}} {"my_location": {"lat":52.370159, "lon":4.885057}, "@timestamp": "2023-01-02T10:00:00Z"} {"index":{}} {"my_location": {"lat":52.369219, "lon":4.901618}, "@timestamp": "2023-01-02T13:00:00Z"} {"index":{}} {"my_location": {"lat":52.374081, "lon":4.912350}, "@timestamp": "2023-01-02T16:00:00Z"} {"index":{}} {"my_location": {"lat":52.371667, "lon":4.914722}, "@timestamp": "2023-01-03T12:00:00Z"} POST /test/_search?filter_path=aggregations { "aggs": { "line": { "geo_line": { "point": {"field": "my_location"}, "sort": {"field": "@timestamp"} } } } }
Which returns:
{ "aggregations": { "line": { "type": "Feature", "geometry": { "type": "LineString", "coordinates": [ [ 4.889187, 52.373184 ], [ 4.885057, 52.370159 ], [ 4.901618, 52.369219 ], [ 4.912350, 52.374081 ], [ 4.914722, 52.371667 ] ] }, "properties": { "complete": true } } } }
The resulting GeoJSON Feature contains both a LineString geometry
for the path generated by the aggregation, as well as a map of properties.
The property complete informs of whether all documents matched were used to generate the geometry.
The size option can be used to limit the number of documents included in the aggregation,
leading to results with complete: false.
Exactly which documents are dropped from results depends on whether the aggregation is based
on time_series or not.
This result could be displayed in a map user interface:
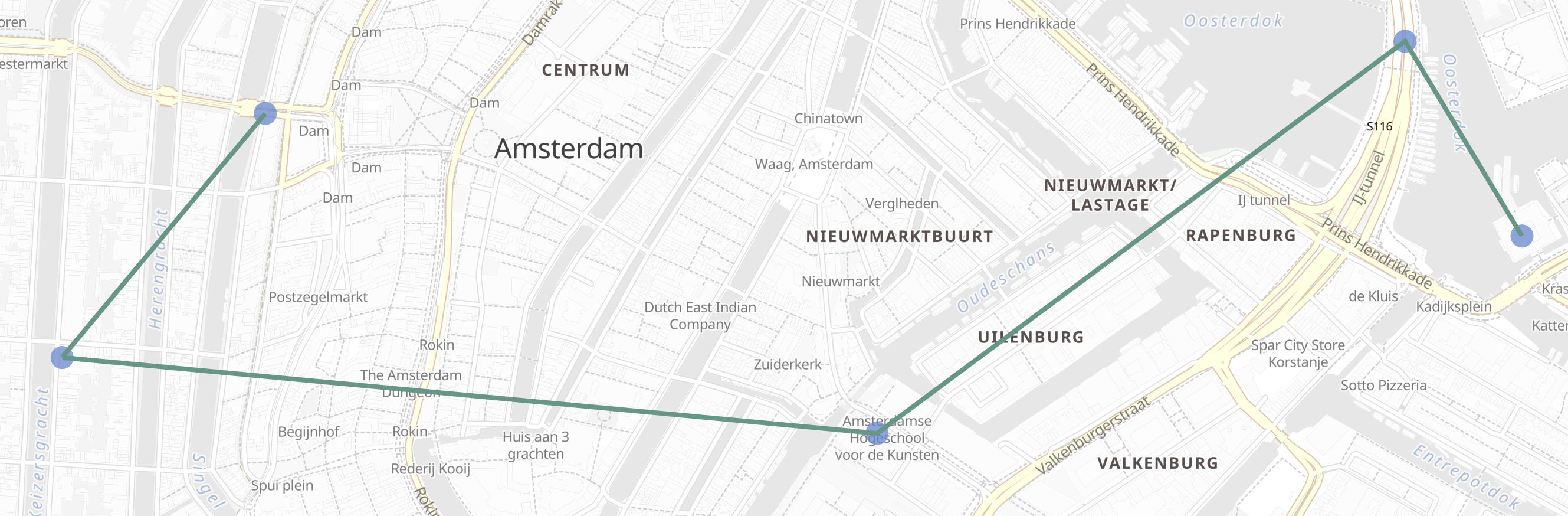
Optionsedit
-
point - (Required)
This option specifies the name of the geo_point field
Example usage configuring my_location as the point field:
"point": { "field": "my_location" }
-
sort -
(Required outside
time_seriesaggregations)
This option specifies the name of the numeric field to use as the sort key for ordering the points.
When the geo_line aggregation is nested inside a
time_series
aggregation, this field defaults to @timestamp, and any other value will result in error.
Example usage configuring @timestamp as the sort key:
"sort": { "field": "@timestamp" }
-
include_sort -
(Optional, boolean, default:
false) This option includes, when true, an additional array of the sort values in the feature properties. -
sort_order -
(Optional, string, default:
"ASC") This option accepts one of two values: "ASC", "DESC". The line is sorted in ascending order by the sort key when set to "ASC", and in descending with "DESC".
-
size -
(Optional, integer, default:
10000) The maximum length of the line represented in the aggregation. Valid sizes are between one and 10000. Withintime_seriesthe aggregation uses line simplification to constrain the size, otherwise it uses truncation. Refer to Why group with time-series? for a discussion on the subtleties involved.
Groupingedit
This simple example produces a single track for all the data selected by the query. However, it is far more common to need to group the data into multiple tracks. For example, grouping flight transponder measurements by flight call-sign before sorting each flight by timestamp and producing a separate track for each.
In the following examples we will group the locations of points of interest in the cities of Amsterdam, Antwerp and Paris. The tracks will be ordered by the planned visit sequence for a walking tour of the museums and others attractions.
In order to demonstrate the difference between a time-series grouping and a non-time-series grouping, we will first create an index with time-series enabled, and then give examples of grouping the same data without time-series and with time-series.
PUT tour { "mappings": { "properties": { "city": { "type": "keyword", "time_series_dimension": true }, "category": { "type": "keyword" }, "route": { "type": "long" }, "name": { "type": "keyword" }, "location": { "type": "geo_point" }, "@timestamp": { "type": "date" } } }, "settings": { "index": { "mode": "time_series", "routing_path": [ "city" ], "time_series": { "start_time": "2023-01-01T00:00:00Z", "end_time": "2024-01-01T00:00:00Z" } } } } POST /tour/_bulk?refresh {"index":{}} {"@timestamp": "2023-01-02T09:00:00Z", "route": 0, "location": "POINT(4.889187 52.373184)", "city": "Amsterdam", "category": "Attraction", "name": "Royal Palace Amsterdam"} {"index":{}} {"@timestamp": "2023-01-02T10:00:00Z", "route": 1, "location": "POINT(4.885057 52.370159)", "city": "Amsterdam", "category": "Attraction", "name": "The Amsterdam Dungeon"} {"index":{}} {"@timestamp": "2023-01-02T13:00:00Z", "route": 2, "location": "POINT(4.901618 52.369219)", "city": "Amsterdam", "category": "Museum", "name": "Museum Het Rembrandthuis"} {"index":{}} {"@timestamp": "2023-01-02T16:00:00Z", "route": 3, "location": "POINT(4.912350 52.374081)", "city": "Amsterdam", "category": "Museum", "name": "NEMO Science Museum"} {"index":{}} {"@timestamp": "2023-01-03T12:00:00Z", "route": 4, "location": "POINT(4.914722 52.371667)", "city": "Amsterdam", "category": "Museum", "name": "Nederlands Scheepvaartmuseum"} {"index":{}} {"@timestamp": "2023-01-04T09:00:00Z", "route": 5, "location": "POINT(4.401384 51.220292)", "city": "Antwerp", "category": "Attraction", "name": "Cathedral of Our Lady"} {"index":{}} {"@timestamp": "2023-01-04T12:00:00Z", "route": 6, "location": "POINT(4.405819 51.221758)", "city": "Antwerp", "category": "Museum", "name": "Snijders&Rockoxhuis"} {"index":{}} {"@timestamp": "2023-01-04T15:00:00Z", "route": 7, "location": "POINT(4.405200 51.222900)", "city": "Antwerp", "category": "Museum", "name": "Letterenhuis"} {"index":{}} {"@timestamp": "2023-01-05T10:00:00Z", "route": 8, "location": "POINT(2.336389 48.861111)", "city": "Paris", "category": "Museum", "name": "Musée du Louvre"} {"index":{}} {"@timestamp": "2023-01-05T14:00:00Z", "route": 9, "location": "POINT(2.327000 48.860000)", "city": "Paris", "category": "Museum", "name": "Musée dOrsay"}
Grouping with termsedit
Using this data, for a non-time-series use case, the grouping can be done using a
terms aggregation based on city name.
This would work whether or not we had defined the tour index as a time series index.
POST /tour/_search?filter_path=aggregations { "aggregations": { "path": { "terms": {"field": "city"}, "aggregations": { "museum_tour": { "geo_line": { "point": {"field": "location"}, "sort": {"field": "@timestamp"} } } } } } }
Which returns:
{ "aggregations": { "path": { "doc_count_error_upper_bound": 0, "sum_other_doc_count": 0, "buckets": [ { "key": "Amsterdam", "doc_count": 5, "museum_tour": { "type": "Feature", "geometry": { "coordinates": [ [ 4.889187, 52.373184 ], [ 4.885057, 52.370159 ], [ 4.901618, 52.369219 ], [ 4.91235, 52.374081 ], [ 4.914722, 52.371667 ] ], "type": "LineString" }, "properties": { "complete": true } } }, { "key": "Antwerp", "doc_count": 3, "museum_tour": { "type": "Feature", "geometry": { "coordinates": [ [ 4.401384, 51.220292 ], [ 4.405819, 51.221758 ], [ 4.4052, 51.2229 ] ], "type": "LineString" }, "properties": { "complete": true } } }, { "key": "Paris", "doc_count": 2, "museum_tour": { "type": "Feature", "geometry": { "coordinates": [ [ 2.336389, 48.861111 ], [ 2.327, 48.86 ] ], "type": "LineString" }, "properties": { "complete": true } } } ] } } }
These results contain an array of buckets, where each bucket is a JSON object with the key showing the name
of the city field, and an inner aggregation result called museum_tour containing a
GeoJSON Feature describing the
actual route between the various attractions in that city.
Each result also includes a properties object with a complete value which will be false if the geometry
was truncated to the limits specified in the size parameter.
Note that when we use time_series in the next example, we will get the same results structured a little differently.
Grouping with time-seriesedit
This functionality is in technical preview and may be changed or removed in a future release. Elastic will apply best effort to fix any issues, but features in technical preview are not subject to the support SLA of official GA features.
Using the same data as before, we can also perform the grouping with a
time_series aggregation.
This will group by TSID, which is defined as the combinations of all fields with time_series_dimension: true,
in this case the same city field used in the previous
terms aggregation.
This example will only work if we defined the tour index as a time series index using index.mode="time_series".
POST /tour/_search?filter_path=aggregations { "aggregations": { "path": { "time_series": {}, "aggregations": { "museum_tour": { "geo_line": { "point": {"field": "location"} } } } } } }
The geo_line aggregation no longer requires the sort field when nested within a
time_series aggregation.
This is because the sort field is set to @timestamp, which all time-series indexes are pre-sorted by.
If you do set this parameter, and set it to something other than @timestamp you will get an error.
This query will result in:
{ "aggregations": { "path": { "buckets": { "{city=Paris}": { "key": { "city": "Paris" }, "doc_count": 2, "museum_tour": { "type": "Feature", "geometry": { "coordinates": [ [ 2.336389, 48.861111 ], [ 2.327, 48.86 ] ], "type": "LineString" }, "properties": { "complete": true } } }, "{city=Antwerp}": { "key": { "city": "Antwerp" }, "doc_count": 3, "museum_tour": { "type": "Feature", "geometry": { "coordinates": [ [ 4.401384, 51.220292 ], [ 4.405819, 51.221758 ], [ 4.4052, 51.2229 ] ], "type": "LineString" }, "properties": { "complete": true } } }, "{city=Amsterdam}": { "key": { "city": "Amsterdam" }, "doc_count": 5, "museum_tour": { "type": "Feature", "geometry": { "coordinates": [ [ 4.889187, 52.373184 ], [ 4.885057, 52.370159 ], [ 4.901618, 52.369219 ], [ 4.91235, 52.374081 ], [ 4.914722, 52.371667 ] ], "type": "LineString" }, "properties": { "complete": true } } } } } } }
These results are essentially the same as with the previous terms aggregation example, but structured differently.
Here we see the buckets returned as a map, where the key is an internal description of the TSID.
This TSID is unique for each unique combination of fields with time_series_dimension: true.
Each bucket contains a key field which is also a map of all dimension values for the TSID, in this case only the city
name is used for grouping.
In addition, there is an inner aggregation result called museum_tour containing a
GeoJSON Feature describing the
actual route between the various attractions in that city.
Each result also includes a properties object with a complete value which will be false if the geometry
was simplified to the limits specified in the size parameter.
Why group with time-series?edit
When reviewing these examples, you might think that there is little difference between using
terms or
time_series
to group the geo-lines. However, there are some important differences in behaviour between the two cases.
Time series indexes are stored in a very specific order on disk.
They are pre-grouped by the time-series dimension fields, and pre-sorted by the @timestamp field.
This allows the geo_line aggregation to be considerably optimized:
- The same memory allocated for the first bucket can be re-used over and over for all subsequent buckets. This is substantially less memory than required for non-time-series cases where all buckets are collected concurrently.
-
No sorting needs to be done, since the data is pre-sorted by
@timestamp. The time-series data will naturally arrive at the aggregation collector inDESCorder. This means that if we specifysort_order:ASC(the default), we still collect inDESCorder, but perform an efficient in-memory reverse order before generating the finalLineStringgeometry. -
The
sizeparameter can be used for a streaming line-simplification algorithm. Without time-series, we are forced to truncate data, by default after 10000 documents per bucket, in order to prevent memory usage from being unbounded. This can result in geo-lines being truncated, and therefor loosing important data. With time-series we can run a streaming line-simplification algorithm, retaining control over memory usage, while also maintaining the overall geometry shape. In fact, for most use cases it would work to set thissizeparameter to a much lower bound, and save even more memory. For example, if thegeo_lineis to be drawn on a display map with a specific resolution, it might look just as good to simplify to as few as 100 or 200 points. This will save memory on the server, on the network and in the client.
Note: There are other significant advantages to working with time-series data and using time_series index mode.
These are discussed in the documentation on time series data streams.
Streaming line simplificationedit
Line simplification is a great way to reduce the size of the final results sent to the client, and displayed in a map
user interface. However, normally these algorithms use a lot of memory to perform the simplification, requiring the
entire geometry to be maintained in memory together with supporting data for the simplification itself.
The use of a streaming line simplification algorithm allows for minimal memory usage during the simplification
process by constraining memory to the bounds defined for the simplified geometry. This is only possible if no sorting
is required, which is the case when grouping is done by the
time_series aggregation,
running on an index with the time_series index mode.
Under these conditions the geo_line aggregation allocates memory to the size specified, and then fills that
memory with the incoming documents.
Once the memory is completely filled, documents from within the line are removed as new documents are added.
The choice of document to remove is made to minimize the visual impact on the geometry.
This process makes use of the
Visvalingam–Whyatt algorithm.
Essentially this means points are removed if they have the minimum triangle area, with the triangle defined
by the point under consideration and the two points before and after it in the line.
In addition, we calculate the area using spherical coordinates so that no planar distortions affect the choice.
In order to demonstrate how much better line simplification is to line truncation, consider this example of the north
shore of Kodiak Island.
The data for this is only 209 points, but if we want to set size to 100 we get dramatic truncation.

The grey line is the entire geometry of 209 points, while the blue line is the first 100 points, a very different geometry than the original.
Now consider the same geometry simplified to 100 points.

For comparison we have shown the original in grey, the truncated in blue and the new simplified geometry in magenta. It is possible to see where the new simplified line deviates from the original, but the overall geometry appears almost identical and is still clearly recognizable as the north shore of Kodiak Island.
On this page