
Getting Started with EnterpriseGraphs
This chapter walks you through the first steps you need to follow to create an EnterpriseGraph
EnterpriseGraphs cannot use existing collections. When switching to EnterpriseGraph from an existing dataset, you have to import the data into a fresh EnterpriseGraph.
When creating an EnterpriseGraph, you cannot have different number of shards per
collection. To preserve the sharding pattern, the _from and _to attributes
of the edges cannot be modified.
You can define any _key value on vertices, including existing ones.
Migrating from Community Edition
When migrating from the Community Edition to the Enterprise Edition, you can
bring data from existing collections using the command-line tools arangoexport
and arangoimport.
arangoexport allows you to export collections to formats like JSON, JSONL, or CSV.
For this particular case, it is recommended to export data to JSONL format.
Once the data is exported, you need to exclude
the _key values from edges. The enterprise-graph module does not allow
custom _key values on edges. This is necessary for the initial data replication
when using arangoimport because these values are immutable.
Migration by Example
Let us assume you have a general-graph in ArangoDB
that you want to migrate over to be an enterprise-graph to benefit from
the sharding strategy. In this example, the graph has only two collections:
old_vertices which is a document collection and old_edges which is the
corresponding edge collection.
Export general-graph data
The first step is to export the raw data of those
collections using arangoexport:
arangoexport --type jsonl --collection old_vertices --output-directory docOutput --overwrite true
arangoexport --type jsonl --collection old_edges --output-directory docOutput --overwrite true
Note that the JSONL format type is being used in the migration process
as it is more flexible and can be used with larger datasets.
The JSON type is limited in amount of documents, as it cannot be parsed line
by line. The CSV and TSV formats are also fine,
but require to define the list of attributes to export. JSONL exports data
as is, and due to its line based layout, can be processed line by line and
therefore has no artificial restrictions on the data.
After this step, two files are generated in the docOutput folder, that
should look like this:
docOutput/old_vertices.jsonl:{"_key":"Alice","_id":"old_vertices/Alice","_rev":"_edwXFGm---","attribute1":"value1"} {"_key":"Bob","_id":"old_vertices/Bob","_rev":"_edwXFGm--_","attribute1":"value2"} {"_key":"Charly","_id":"old_vertices/Charly","_rev":"_edwXFGm--B","attribute1":"value3"}docOutput/old_edges.jsonl:{"_key":"121","_id":"old_edges/121","_from":"old_vertices/Bob","_to":"old_vertices/Charly","_rev":"_edwW20----","attribute2":"value2"} {"_key":"122","_id":"old_edges/122","_from":"old_vertices/Charly","_to":"old_vertices/Alice","_rev":"_edwW20G---","attribute2":"value3"} {"_key":"120","_id":"old_edges/120","_from":"old_vertices/Alice","_to":"old_vertices/Bob","_rev":"_edwW20C---","attribute2":"value1"}
Create new Graph
The next step is to set up an empty EnterpriseGraph and configure it according to your preferences.
You are free to change numberOfShards, replicationFactor, or even collection names at this point.
Please follow the instructions on how to create an EnterpriseGraph using the Web Interface or using arangosh.
Import data while keeping collection names
This example describes a 1:1 migration while keeping the original graph intact and just changing the sharding strategy.
The empty collections that are now in the target ArangoDB cluster, have to be filled with data. All vertices can be imported without any change:
arangoimport --collection old_vertices --file docOutput/old_vertices.jsonl
On the edges, EnterpriseGraphs disallow storing the _key value, so this attribute
needs to be removed on import:
arangoimport --collection old_edges --file docOutput/old_edges.jsonl --remove-attribute "_key"
After this step, the graph has been migrated.
Import data while changing collection names
This example describes a scenario in which the collections names have changed,
assuming that you have renamed old_vertices to vertices.
For the vertex data this change is not relevant, the _id values is adjust automatically,
so you can import the data again, and just target the new collection name:
arangoimport --collection vertices --file docOutput/old_vertices.jsonl
For the edges you need to apply more changes, as they need to be rewired.
First thing, you have to remove the _key value as it is disallowed for
EnterpriseGraphs.
Second, because you have changed the name of the _from collection, you need
to provide a from-collection-prefix. The same is true for the _to collection.
Note that you can only change all vertices on _from respectively _to
side with this mechanism. However, you can use different collections on _from and _to.
Next, in order to make the change of vertex collection you need to
allow overwrite-collection-prefix.
If this flag is not set, only values without any given collection are changed.
This is helpful if your data is not exported by ArangoDB in the first place.
Now that you have everything together, run the following command:
arangoimport --collection edges --file docOutput/old_edges.jsonl --remove-attribute "_key" --from-collection-prefix "vertices" --to-collection-prefix "vertices" --overwrite-collection-prefix true
After this step, the graph has been migrated and also changed to new collection names.
Collections in EnterpriseGraphs
In contrast to General Graphs, you cannot use existing collections. When switching from an existing dataset, you have to import the data into a fresh EnterpriseGraph.
The creation of an EnterpriseGraph graph requires the name of the graph and a
definition of its edges. All collections used within the creation process are
automatically created by the enterprise-graph module. Make sure to only use
non-existent collection names for both vertices and edges.
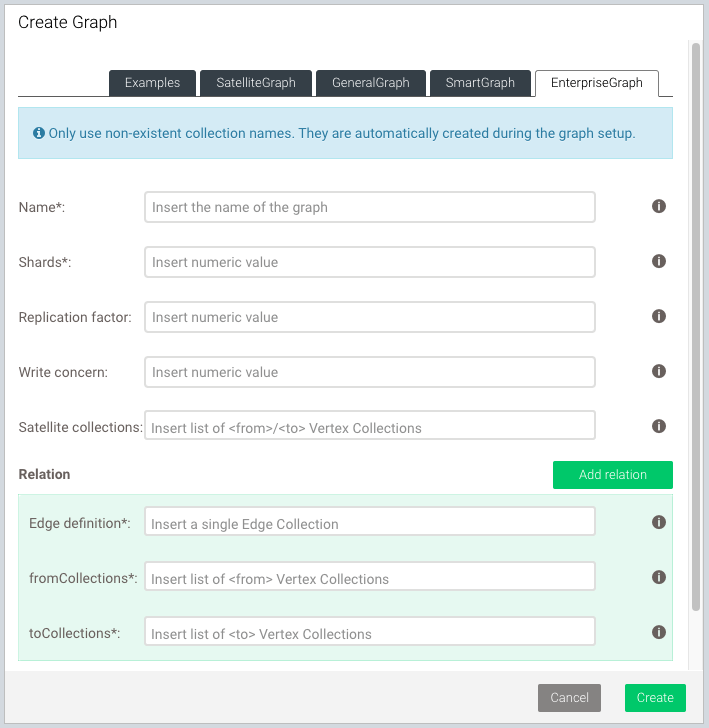
Create an EnterpriseGraph using the Web Interface
The Web Interface (also called Web UI) allows you to easily create and manage EnterpriseGraphs. To get started, follow the steps outlined below.
- In the main page of the Web Interface, go to the left sidebar menu and select the Graphs tab.
- To add a new graph, click Add Graph.
- In the Create Graph dialog that appears, select the EnterpriseGraph tab.
- Fill in all required fields:
- For Name, enter a name for the EnterpriseGraph.
- For Shards, enter the number of shards the graph is using.
- Optional: For Replication factor, enter the total number of desired copies of the data in the cluster.
- Optional: For Write concern, enter the total number of copies of the data in the cluster required for each write operation.
- Optional: For SatelliteCollections, insert vertex collections that are being used in your edge definitions. These collections are then created as satellites, and thus replicated to all DB-Servers.
- For Edge definition, insert a single non-existent name to define
the relation of the graph. This automatically creates a new edge
collection, which is displayed in the Collections tab of the
left sidebar menu.
To define multiple relations, press the Add relation button. To remove a relation, press the Remove relation button.
- For fromCollections, insert a list of vertex collections that contain the start vertices of the relation.
- For toCollections, insert a list of vertex collections that contain the end vertices of the relation.
Insert only non-existent collection names. Collections are automatically created during the graph setup and are displayed in the Collections tab of the left sidebar menu.
- For Orphan collections, insert a list of vertex collections that are part of the graph but not used in any edge definition.
- Click Create.
- Open the graph and use the functions of the Graph Viewer to visually interact with the graph and manage the graph data.
Create an EnterpriseGraph using arangosh
Compared to SmartGraphs, the option isSmart: true is required but the
smartGraphAttribute is forbidden.
arangosh> var graph_module = require("@arangodb/enterprise-graph");
arangosh> var graph = graph_module._create("myGraph", [], [], {isSmart: true, numberOfShards: 9});
arangosh> graph_module._graph("myGraph");
{[EnterpriseGraph]
}
Add vertex collections
The collections must not exist when creating the EnterpriseGraph. The EnterpriseGraph module creates them for you automatically to set up the sharding for all these collections correctly. If you create collections via the EnterpriseGraph module and remove them from the graph definition, then you may re-add them without trouble however, as they have the correct sharding.
arangosh> graph._addVertexCollection("shop");
arangosh> graph._addVertexCollection("customer");
arangosh> graph._addVertexCollection("pet");
arangosh> graph_module._graph("myGraph");
{[EnterpriseGraph]
"customer" : [ArangoCollection 10202, "customer" (type document, status loaded)],
"pet" : [ArangoCollection 10213, "pet" (type document, status loaded)],
"shop" : [ArangoCollection 10191, "shop" (type document, status loaded)]
}
Define relations on the Graph
Adding edge collections works the same as with General Graphs, but again, the collections are created by the EnterpriseGraph module to set up sharding correctly so they must not exist when creating the EnterpriseGraph (unless they have the correct sharding already).
Create an EnterpriseGraph using SatelliteCollections
When creating a collection, you can decide whether it’s a SatelliteCollection
or not. For example, a vertex collection can be satellite as well.
SatelliteCollections don’t require sharding as the data is distributed
globally on all DB-Servers. The smartGraphAttribute is also not required.
In addition to the attributes you would set to create a EnterpriseGraph, there is an
additional attribute satellites you can optionally set. It needs to be an array of
one or more collection names. These names can be used in edge definitions
(relations) and these collections are created as SatelliteCollections.
However, all vertex collections on one side of the relation have to be of
the same type - either all satellite or all smart. This is because _from
and _to can have different types based on the sharding pattern.
In this example, both vertex collections are created as SatelliteCollections.
When providing a satellite collection that is not used in a relation, it is not created. If you create the collection in a following request, only then the option counts.
arangosh> var graph_module = require("@arangodb/enterprise-graph");
arangosh> var rel = graph_module._relation("isCustomer", "shop", "customer")
arangosh> var graph = graph_module._create("myGraph", [rel], [], {satellites: ["shop", "customer"], isSmart: true, numberOfShards: 9});
arangosh> graph_module._graph("myGraph");
{[EnterpriseGraph]
"isCustomer" : [ArangoCollection 10312, "isCustomer" (type edge, status loaded)],
"shop" : [ArangoCollection 10310, "shop" (type document, status loaded)],
"customer" : [ArangoCollection 10311, "customer" (type document, status loaded)]
}