Implement a custom query module in Python
This tutorial will give you a basic idea of how to develop a custom query module in Python with Memgraph Lab 2.0 and use it on a dataset.
In short, query modules allow you to expand the Cypher query module with various procedures. Procedures can be written in Python or C languages. Our MAGE library has various modules dealing with complex graph algorithms, but you can implement your own procedures gathered in query modules to optimize your queries. If you need more information about what query modules are, please read our reference guide on query modules.
Prerequisites
In order to start developing a custom query you will need:
Data model
For this tutorial, we will use the Europe backpacking data model with the data from The European Backpacker Index (2018). The data set contains information about 56 cities from 36 European countries, such as what cities are close, what countries border each other, various pricing and recommended accommodation.
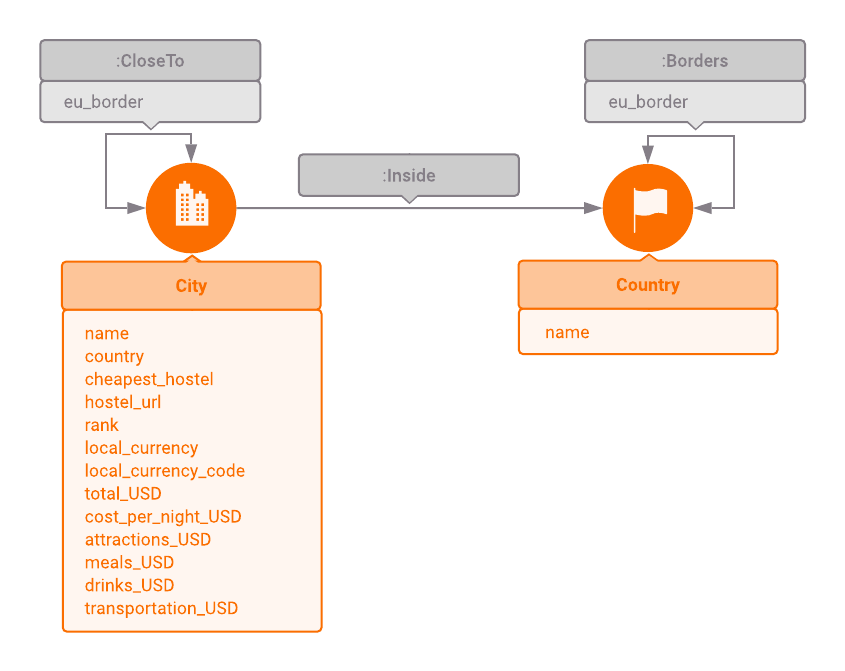
A detailed explanation of the data model
In this tutorial, we will mostly focus on the two nodes, :City and :Country,
and their :Inside relationship.
Preparing Memgraph
Let's open Memgraph Lab where we will import the dataset, as well as write and use the procedures from our query module.
If you have successfully installed Memgraph Platform, you should be able to open
Memgraph Lab in a browser at http://localhost:3000/.
If you are using Memgraph Cloud, open the running instance, and open the Connect via Client tab, then click on Connect in Browser to open Memgraph Lab in a new browser tab. Enter your project password and Connect Now.
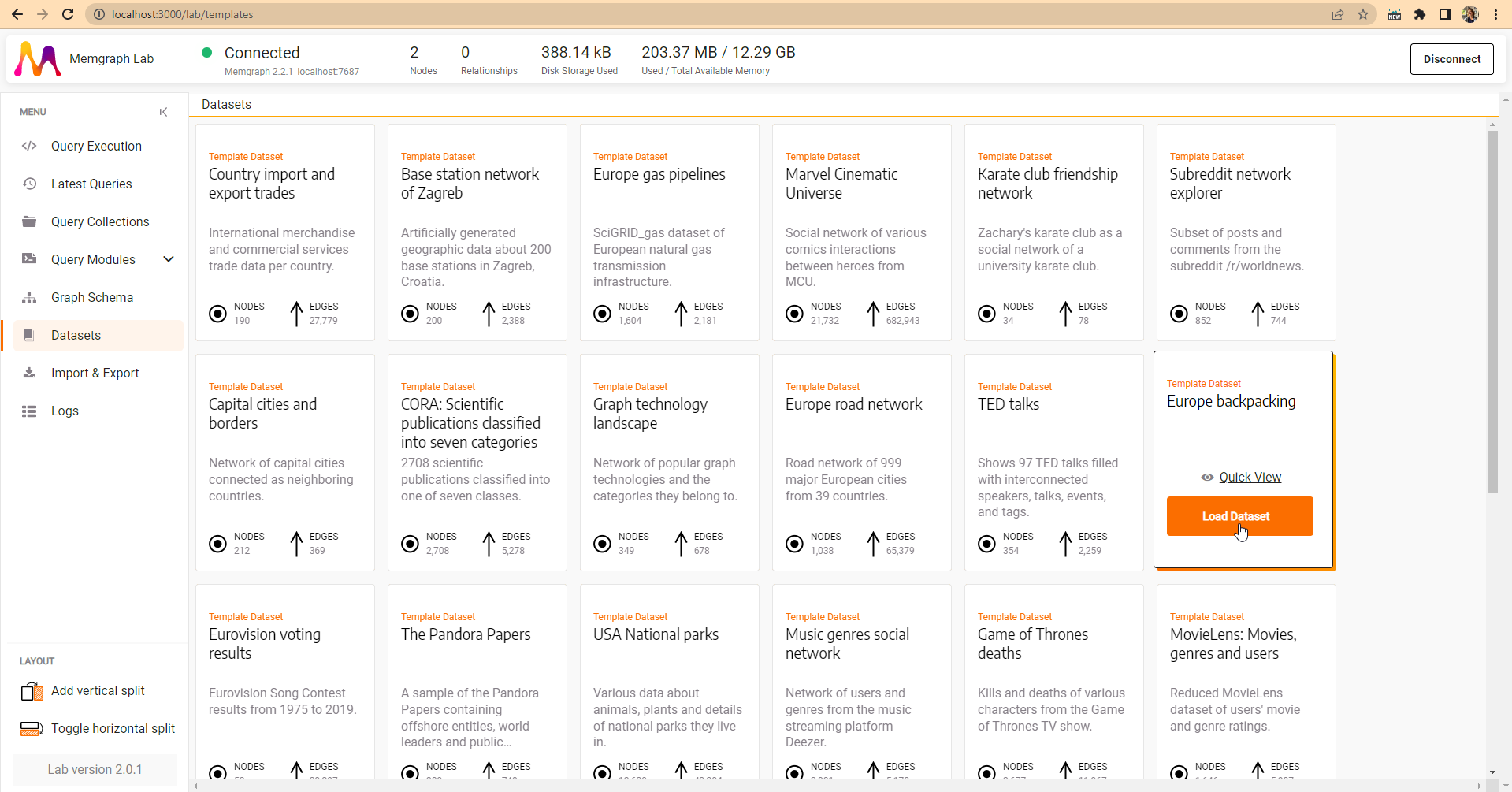
In Memgraph Lab, navigate to the Datasets menu item, click on the Europe backpacking dataset to import it into Memgraph. You can also check the details of the dataset by clicking on Quick View
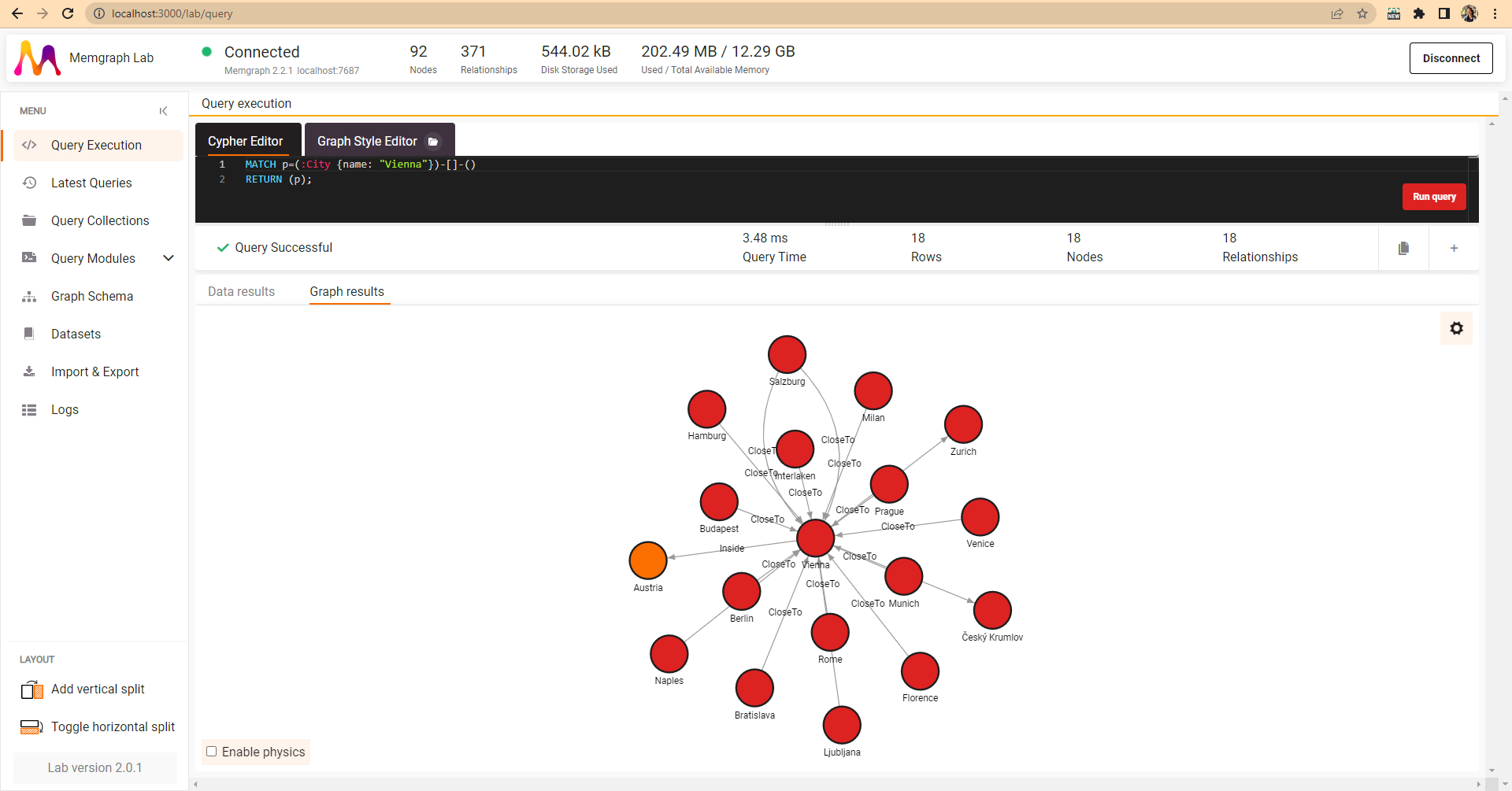
Go to the Query Execution and try running a test query that will show the city Vienna and all its relationships:
MATCH p=(:City {name: "Vienna"})-[]-()
RETURN (p);
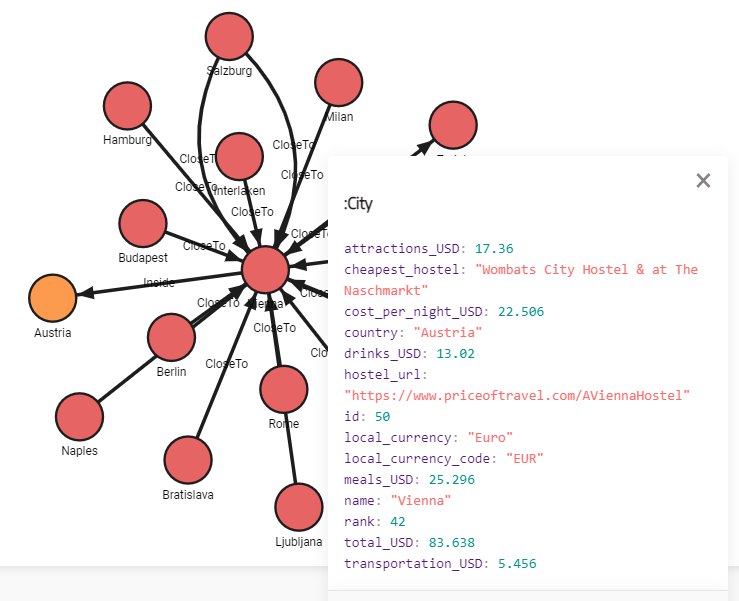
You can click on the :City nodes to check the nodes' properties and get better
acquainted with the dataset. We will come back to this view every time we want
to test our query modules in making.
Now navigate to Query Modules. Here you can see all the query modules
available in Memgraph, such as utility modules or query modules from the MAGE
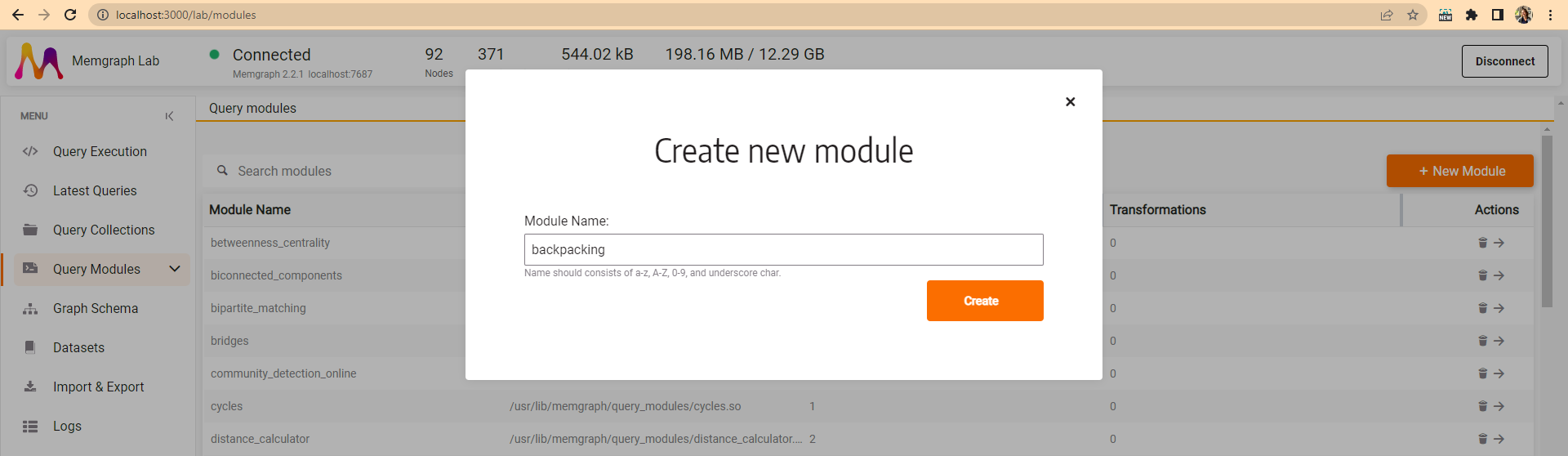
library. To create a new custom query module, click on the New Module
button, give the new module name backpacking and create the module. Memgraph
Lab creates sample procedures to kick off your development. But before we start,
let's decide how we will expand the query language.
Goals
Before we start to write a query module and procedures within, we need goals. How do we want to expand the query language?
Goal 1: We want to get a total cost of accommodation expenses for one night at the cheapest hostel in a given city, based on the number of adults and children that will be staying in it.
Goal 2: We also want to expand the data model by a given country and city.
The new City node should get properties that it shares with the other cities
in that country, such as country, local_currency and local_currency_code.
Python API
Python API is defined in the mgp module you can find in the Memgraph
installation directory /usr/lib/memgraph/python_support. If you are using
Docker, you can copy the file from the Docker container into your computer for
faster access.
Copy the mgp module from a Docker container
In essence, Python API is a wrapper around the C API. If you look at row 15 of
the new module we've created in Memgraph Lab, you can see you need to import the
mgp module at the beginning of every query module.
Below the import mgp, in line 17, you can see a @read_proc decorator. Python
API defines @mgp.read_proc, @mgp.write_proc and @mgp.transformation
decorators. @mgp.read_proc decorator handles read-only procedures, the
@mgp.write_proc decorator handles procedures that also write to the database,
and the @mgp.transformation decorator handles data coming from streams.
If you look at our two goals, to get the total cost of accommodation, Memgraph
only needs to read from the database to get the value of the
cost_per_night_USD, while to create new nodes it also needs to write in the
database.
Feel free to examine the examples and tips available in this template, and when you are ready to continue with the tutorial, clear the file so we start writing our code from line 1.
We'll start with the @mgp.read_proc decorator to achieve the first goal, then
we'll dive into a bit more complicated second goal and its @mgp.write_proc.
Read procedure
As we established in the previous chapter, first we need to import the mgp
module and then use the @mgp.read_proc decorator. Then we will define the
procedure by giving it a name and signature, that is, what arguments it needs to
receive and what values it will return.
The goal of this procedure is to get a total cost of accommodation expenses for one night at the cheapest hostel in a given city, based on the number of adults and children that will be staying in it.
So, let's name the procedure total_cost. The procedure needs to receive the
following arguments in order to calculate the total cost of accommodation:
- the whole graph (all the nodes and relationships)
- the name of the city we are interested in
- the number of adults staying at the accommodation
- the number of children.
The graph is passed to the procedure using the ProcCtx instance. The name of
the city should be a string value, the number of adults an integer, and the
number of children also an integer. Because customers can travel with or without
children, we will define the children variable as optional by giving it a
possibility to be NULL and setting it to a default value of None.
Output values are defined as arguments of the Record class. We want the
function to return the total cost per night as a float value, and we'll enable
the value to be NULL so that the procedure doesn't return an error if the city
doesn't have the cost of accommodation as a property and thus can't calculate
the total cost of accommodation.
After defining the name and signature, the code should look like this:
import mgp
@mgp.read_proc
def total_cost(context: mgp.ProcCtx,
city: str,
adults: int,
children: mgp.Nullable[int] = None
) -> mgp.Record(Total_cost_per_night = mgp.Nullable[float]):
Now we want to go through all the nodes (vertices) in our graph and find only those nodes that have both:
- the property
namewith the same value as the variablecity - the property
cost_pre_night_USDwith a float value.
import mgp
@mgp.read_proc
def total_cost(context: mgp.ProcCtx,
city: str,
adults: int,
children: mgp.Nullable[int] = None
) -> mgp.Record(Total_cost_per_night = mgp.Nullable[float]):
for vertex in context.graph.vertices:
if vertex.properties["name"] == city and isinstance(vertex.properties.get("cost_per_night_USD"),float):
When we find those nodes, we will save the cost of accommodation per night in a
variable cost_per_night and multiply it with the number of adults to get the
total_cost.
import mgp
@mgp.read_proc
def total_cost(context: mgp.ProcCtx,
city: str,
adults: int,
children: mgp.Nullable[int] = None
) -> mgp.Record(Total_cost_per_night = mgp.Nullable[float]):
for vertex in context.graph.vertices:
if vertex.properties["name"] == city and isinstance(vertex.properties.get("cost_per_night_USD"),float):
cost_per_night = vertex.properties.get("cost_per_night_USD")
total_cost = cost_per_night * adults
Then we need to check if the number of children was given as an argument when calling the procedure in query, and if it was, add half the cost of accommodation for each child. At the end, we return the total cost of accommodation per night.
import mgp
@mgp.read_proc
def total_cost(context: mgp.ProcCtx,
city: str,
adults: int,
children: mgp.Nullable[int] = None
) -> mgp.Record(Total_cost_per_night = mgp.Nullable[float]):
for vertex in context.graph.vertices:
if vertex.properties["name"] == city and isinstance(vertex.properties.get("cost_per_night_USD"),float):
cost_per_night = vertex.properties.get("cost_per_night_USD")
total_cost = cost_per_night * adults
if children is not None:
total_cost += cost_per_night / 2 * children
return mgp.Record(Total_cost_per_night = total_cost)
If none of the nodes have both the property name with the same value as the
variable city nor the property cost_pre_night_USD with a float value, we
will set the value of Total_cost_per_night to None (that is, NULL) in
order to prevent the procedure from generating an error.
The finished procedure now looks like this:
import mgp
@mgp.read_proc
def total_cost(context: mgp.ProcCtx,
city: str,
adults: int,
children: mgp.Nullable[int] = None
) -> mgp.Record(
Total_cost_per_night = mgp.Nullable[float]):
for vertex in context.graph.vertices:
if vertex.properties["name"] == city and isinstance(vertex.properties.get("cost_per_night_USD"),float):
cost_per_night = vertex.properties.get("cost_per_night_USD")
total_cost = cost_per_night * adults
if children is not None:
total_cost += cost_per_night / 2 * children
return mgp.Record(Total_cost_per_night = total_cost)
return mgp.Record(Total_cost_per_night = None)
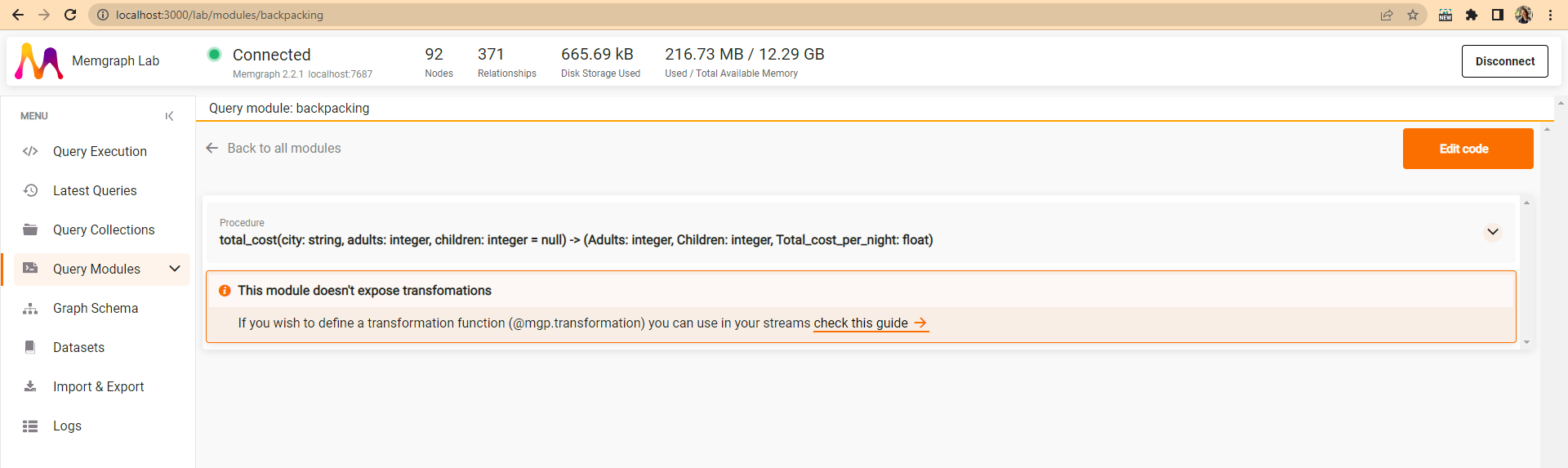
Save and close the query module. You will get an overview of the module that lists procedures and their signature.
Testing the read procedure
Switch to Query Execution and call the procedure using the clause CALL,
then calling the right module and procedure within it
(backpacking.total_cost). List all arguments except the whole graph inside
brackets, and at the end YIELD all the results:
CALL backpacking.total_cost("Zagreb", 2, 3) YIELD *;
Result -> Total_cost_per_night = 32.129999999999995
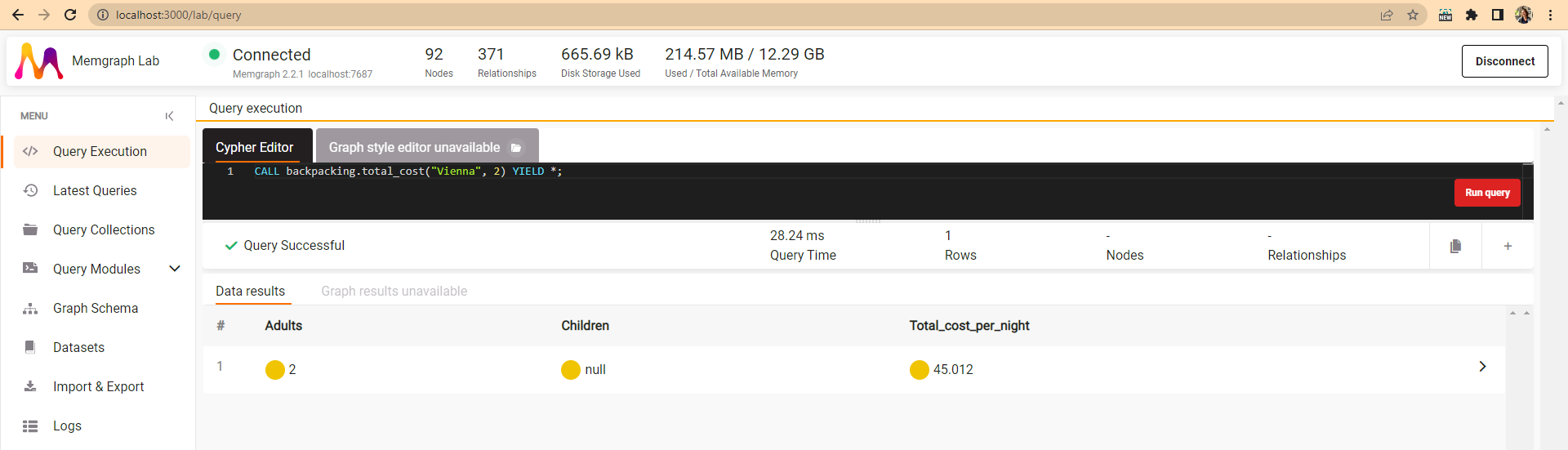
CALL backpacking.total_cost("Vienna", 2) YIELD *;
Result -> Total_cost_per_night = 45.012
CALL backpacking.total_cost("Whatever", 2) YIELD *;
Result -> Total_cost_per_night = null
Detecting errors
Some errors will be written out as you are trying to call the procedure. Others can be viewed in the log file.
If you started your Memgraph Platform image by exposing the 7444 port, you can
check the logs from Memgraph Lab. Otherwise, you need to access the logs in the
Docker container.
But the rest of the errors in the code will result in the procedure not being detected. That means that if you go to the Query Modules menu item and check module details by clicking on the arrow on the right, the procedure with an error will not be listed.
Write procedure
You can continue writing the write procedure below the read procedure. To edit
the current module go to Query Modules and find the backpacking module.
Click on the arrow to view details about the module, such as the name of the
procedures and their signatures. To continue editing the module, click on Edit
code. If you are writing the write procedure in a new module, don't forget to
import the mgp module. For the write procedure, we will use the @mgp.write_proc
decorator.
The goal of this write procedure is to expand the data model by a given country
and city. The new City node should get properties that it shares with the
other cities in that country, such as country, local_currency and
local_currency_code.
Let's name the procedure new_city. The procedure needs to receive the
following arguments in order to create two new nodes and connect them:
- the whole graph (all the nodes and relationships)
- the name of the city
- the name of the country.
The graph is passed to the procedure using the ProcCtx instance. The names of
the city and country should be of string values.
Output values are defined as arguments of the Record class. We want the
function to return the city and country nodes and their relationship.
After defining the name and signature, the code should look like this:
@mgp.write_proc
def new_city(context: mgp.ProcCtx,
in_city: mgp.Nullable[str],
in_country: mgp.Nullable[str]
) -> mgp.Record(City = mgp.Vertex,
Relationship = mgp.Edge,
Country = mgp.Vertex):
We will gradually expand our code to cover all three cases:
- the city and country nodes already exist
- the country node exists but the city node doesn't
- neither the country node nor the city node exist
The city and country nodes already exist
We want to check if the city and country passed as arguments already exist in
the database because if they do, there is no need to create them. We can just
return them as a result. Because the City nodes also include the country
property, we can only check City nodes to find out if a certain city inside a
certain country already exists.
So let's go through all the nodes (vertices) in the graph to check if there is a
node with the country property of the same value as the in_country argument.
If there is, let's check if the name property of that nodes is of the same
value as the as the in_city argument. If there is, it means there are already
City and Country nodes with the same name properties as the in_city and
in_country arguments.
To return the relationship between them, we need to go through all the
relationships from the City node and find the one with type Inside. Then we
will save the destination node in the country variable, and return both nodes
and the relationship.
@mgp.write_proc
def new_city(context: mgp.ProcCtx,
in_city: mgp.Nullable[str],
in_country: mgp.Nullable[str]
) -> mgp.Record(City = mgp.Vertex,
Relationship = mgp.Edge,
Country = mgp.Vertex):
for v in context.graph.vertices:
if v.properties.get("country") == in_country:
if v.properties.get("name") == in_city:
for r in v.out_edges:
if r.type == "Inside":
country = r.to_vertex
return mgp.Record(City=v, Relationship=r, Country=country)
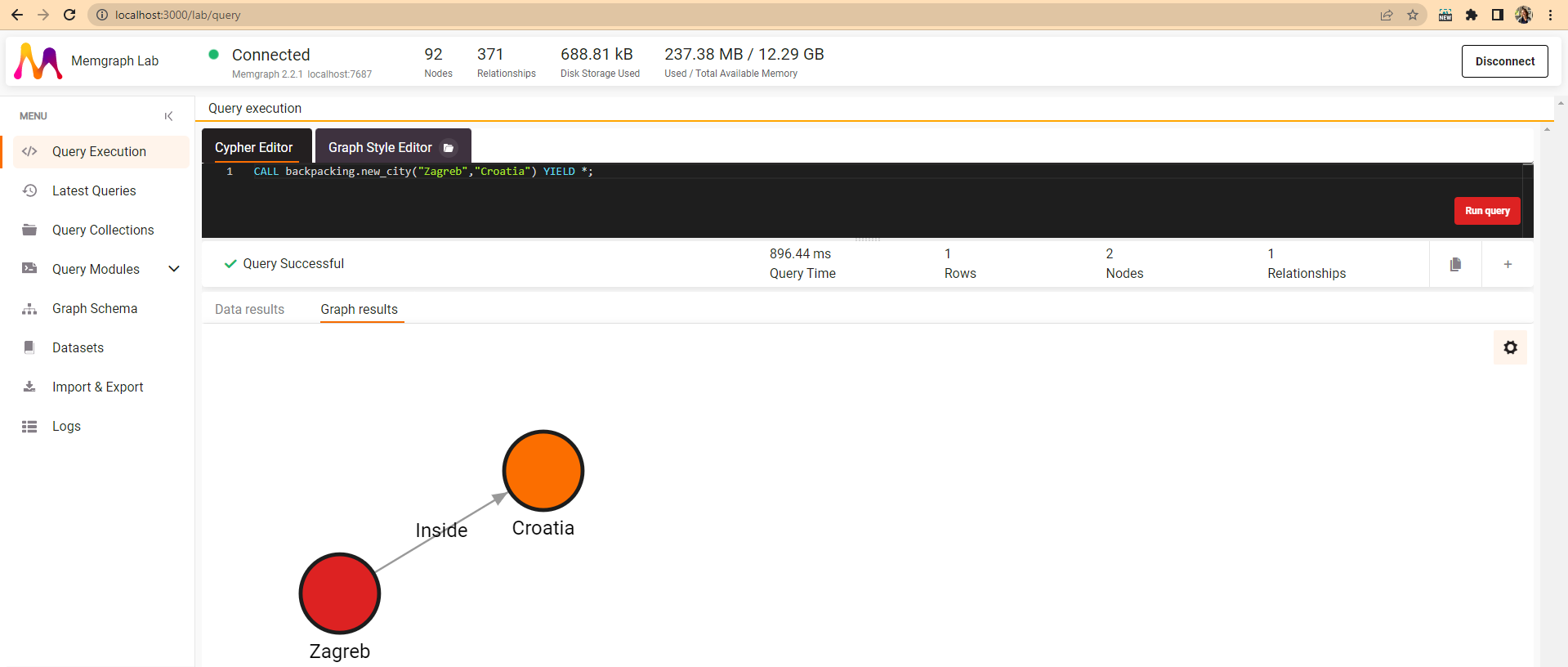
At this point you can save the module and test the new procedure, by running the following query:
CALL backpacking.new_city("Zagreb","Croatia") YIELD *;
The country node exists but the city node doesn't
In the case that the Country node with that name exists, but the City node
doesn't, we should create a new City node, and connect it with the existing
Country node. Because the City nodes have properties about the country they
are connected to, we will use the existing City nodes to copy property values
to the new City node, such as local_currency and local_currency_code.
The new City node also has to get a new id number, that's why we will save
the highest existing id among City nodes in the city_id and increase that
number by 1 to get the ID of the new City node. Now that we have created a new
City node, we need to create a relationship to connect it with the existing
Country node and return both nodes and the relationship.
@mgp.write_proc
def new_city(context: mgp.ProcCtx,
in_city: mgp.Nullable[str],
in_country: mgp.Nullable[str]
) -> mgp.Record(City = mgp.Vertex,
Relationship = mgp.Edge,
Country = mgp.Vertex):
city_id = 0
currency = None
currency_code = None
for v in context.graph.vertices:
label, = v.labels # get node label
if (label == "City") and (v.properties.get("id") > city_id): # the following 2 lines are getting the highest ID
city_id = v.properties.get("id")
if v.properties.get("country") == in_country:
currency = v.properties.get("local_currency") # the following 2 lines are saving property values
currency_code = v.properties.get("local_currency_code")
if v.properties.get("name") == in_city:
for r in v.out_edges:
if r.type == "Inside":
country = r.to_vertex
return mgp.Record(City=v, Relationship=r, Country=country)
city = context.graph.create_vertex() # creating a new node with properties
city.add_label("City")
city.properties.set("id", city_id + 1)
city.properties.set("name", in_city)
city.properties.set("country", in_country)
city.properties.set("local_currency", currency)
city.properties.set("local_currency_code", currency_code)
for v in context.graph.vertices: # creating a new relationship to an existing country
if v.properties.get("name") == in_country:
context.graph.create_edge(city, v, mgp.EdgeType("Inside"))
for r in city.out_edges:
if r.type == "Inside":
return mgp.Record(City=city, Relationship=r, Country=v)
At this point you can save the module and test the new additions to the procedure, by running the following query:
CALL backpacking.new_city("Makarska","Croatia") YIELD *;
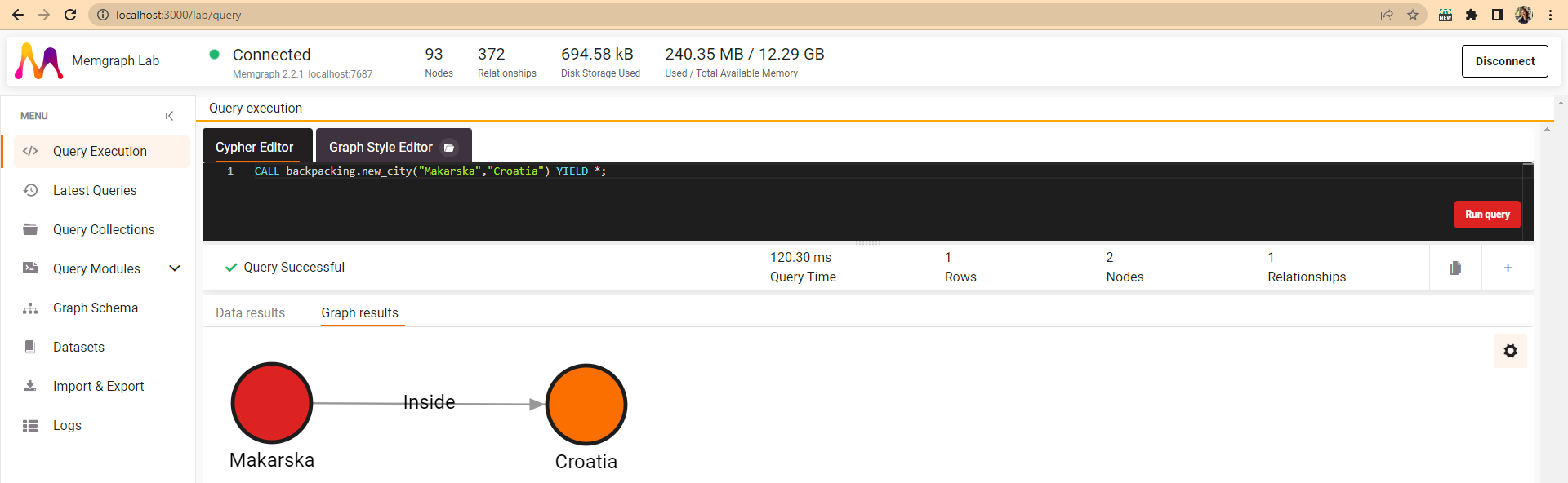
Neither the country node nor the city node exist
Lastly, in the case there is no City node nor Country node with the name
properties the same as the provided arguments, we need to create both.
That is why we also need to find the largest ID among the Country nodes.
Because we only need to create a new Country node if one doesn't exist, we
will introduce a country_exists variable with a default value False. The
value of that flag will change to True only if both the Country node with the
name property the same as the in_country argument exists.
This is also the finished procedure:
@mgp.write_proc
def new_city(context: mgp.ProcCtx,
in_city: mgp.Nullable[str],
in_country: mgp.Nullable[str]
) -> mgp.Record(City = mgp.Vertex,
Relationship = mgp.Edge,
Country = mgp.Vertex):
in_country_exists = False
country_id = 0
city_id = 0
currency = None
currency_code = None
for v in context.graph.vertices:
label, = v.labels # get node label
if (label == "City") and (v.properties.get("id") > city_id): # the following 4 lines are getting the highest IDs
city_id = v.properties.get("id")
if (label == "Country") and (v.properties.get("id") > country_id):
country_id = v.properties.get("id")
if v.properties.get("country") == in_country:
country_exists = True # flag is changed to `True`
currency = v.properties.get("local_currency")
currency_code = v.properties.get("local_currency_code")
if v.properties.get("name") == in_city:
for r in v.out_edges:
if r.type == "Inside":
country = r.to_vertex
return mgp.Record(City=v, Relationship=r, Country=country)
city = context.graph.create_vertex() # creating a new node with properties
city.add_label("City")
city.properties.set("id", city_id + 1)
city.properties.set("name", in_city)
city.properties.set("country", in_country)
city.properties.set("local_currency", currency)
city.properties.set("local_currency_code", currency_code)
if in_country_exists == True: # creating a relationship if the country node exist
for v in context.graph.vertices: # creating a new relationship to an existing country
if v.properties.get("name") == in_country:
context.graph.create_edge(city, v, mgp.EdgeType("Inside"))
for r in city.out_edges:
if r.type == "Inside":
return mgp.Record(City=city, Relationship=r, Country=v)
if in_country_exists == False: # creating a node and relationship if the country node doesn't exist
new_country = context.graph.create_vertex()
new_country.add_label("Country")
new_country.properties.set("id", country_id + 1)
new_country.properties.set("name", in_country)
context.graph.create_edge(city, new_country, mgp.EdgeType("Inside"))
for r in city.out_edges:
if r.type == "Inside":
return mgp.Record(City=city, Relationship=r, Country=new_country)
Testing the write procedure
Save the query module, switch to Query Execution and call the procedure
using the clause CALL, then calling the right module and procedure within it
(backpacking.new_city). List all arguments except the whole graph inside
brackets, and at the end YIELD all the results:
CALL backpacking.new_city("Zagreb", "Croatia") YIELD *;
The query returns existing City and Country nodes.
CALL backpacking.new_city("Vinkovci", "Croatia") YIELD *;
The query returns new City node connected to an existing Country node.
CALL backpacking.new_city("Vinkovci", "Makroland") YIELD *;
The query returns a new City node connected to a new Country node.
Where to next?
Congratulations! You've written your first custom query module! Feel free to play around with the Python API and let us know what you are working on through our Discord server.