Graph stream processing with Kafka and Memgraph
In this tutorial, you will learn how to connect Memgraph to an existing Kafka stream using Memgraph Lab, and transform data into graph database objects to analyze it in real-time.
If you are still very new to streaming, feel free to first read some of our blog posts about the topic to learn what stream processing is, how it differs from batch processing and how streaming databases work.
Now that you've covered theory, let's dive into practice!
We will focus on processing real-time movie ratings that are streamed through MovieLens Kafka stream from the Awesome Data Stream using Memgraph Lab and the Cypher query language.
Prerequisites
To follow this tutorial, you will need:
You can use Memgraph Cloud for a 2-week trial period, or you can install Memgraph Platform locally.
Data stream
For this tutorial, we will use MovieLens Kafka stream from the Awesome Data Stream. MovieLens data stream streams movie ratings, and each JSON message represents a new movie rating:
"userId": "112",
"movie": {
"movieId": "4993",
"title": "Lord of the Rings: The Fellowship of the Ring, The (2001)",
"genres": ["Adventure", "Fantasy"]
},
"rating": "5",
"timestamp": "1442535783"
1. Prepare Memgraph
Let's open Memgraph Lab, where we will write the transformation module and connect to the stream.
If you have successfully installed Memgraph Platform, you should be able to open
Memgraph Lab in a browser at http://localhost:3000/.
If you are using Memgraph Cloud, open the running instance, and open the Connect via Client tab, then click on Connect in Browser to open Memgraph Lab in a new browser tab. Enter your project password and Connect Now.
2. Create a transformation module
The prerequisite of connecting Memgraph to a stream is to have a transformation module with procedures that can produce Cypher queries based on the received messages. Procedures can be written in Python or C languages. If you need more information about what transformation modules are, please read our reference guide on transformation modules.
Memgraph Lab allows you to develop Python transformation modules in-app:
Navigate to Query Modules. Here you can see all the query modules available in Memgraph, such as utility modules or query modules from the MAGE library. Here you will also be able to check out and edit any transformation modules you develop while using Memgraph.
Click on the + New Module button, give the new module name
movielensand create the module.Memgraph Lab creates sample procedures you can erase, so you have a clean slate for writing the
movielenstransformation module.
Python API
Python API is defined in the mgp module you can find in the Memgraph
installation directory /usr/lib/memgraph/python_support. In essence, Python
API is a wrapper around the C API, and at the beginning of each new module, you
need to import the mgp. As the messages from the streams are coming as JSON
messages, you need to import json module for Memgraph to read them correctly.
Below the imported modules, you need to define the @mgp.transformation
decorator, which handles data coming from streams.
Python API also defines @mgp.read_proc and @mgp.write_proc decorators.
@mgp.read_proc decorator handles read-only procedures, the @mgp.write_proc
decorator handles procedures that also write to the database and they are used
in writing custom query
modules.
import mgp
import json
@mgp.transformation
Now you are ready to write the function that will transform JSON messages to graph entities.
Transformation function
First, define the function rating that will receive a list of messages and return
queries that will be executed in Memgraph as any regular query in order to
create nodes and relationships, so the signature of the function looks like this:
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
Now you need to iterate through each message within the batch, decode it with
json.loads and save the elements of the message in the movie_dict variable.
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
movie_dict = json.loads(message.payload().decode('utf8'))
Now, you create the queries that will execute in Memgraph. You instruct Memgraph
to create User, Movie and Genre nodes, then connect the nodes with
appropriate relationships. In each query, you also define the entity properties.
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
movie_dict = json.loads(message.payload().decode('utf8'))
result_queries.append(
mgp.Record(
query=("MERGE (u:User {id: $userId}) "
"MERGE (m:Movie {id: $movieId, title: $title}) "
"WITH u, m "
"UNWIND $genres as genre "
"MERGE (m)-[:OF_GENRE]->(:Genre {name: genre}) "
"MERGE (u)-[r:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)"),
Once you set the placeholders, you can fill them out by applying the values from the messages to the node and relationship properties, and return the queries.
import mgp
import json
@mgp.transformation
def rating(messages: mgp.Messages
) -> mgp.Record(query=str, parameters=mgp.Nullable[mgp.Map]):
result_queries = []
for i in range(messages.total_messages()):
message = messages.message_at(i)
movie_dict = json.loads(message.payload().decode('utf8'))
result_queries.append(
mgp.Record(
query=("MERGE (u:User {id: $userId}) "
"MERGE (m:Movie {id: $movieId, title: $title}) "
"WITH u, m "
"UNWIND $genres as genre "
"MERGE (m)-[:OF_GENRE]->(:Genre {name: genre}) "
"MERGE (u)-[r:RATED {rating: ToFloat($rating), timestamp: $timestamp}]->(m)"),
parameters={
"userId": movie_dict["userId"],
"movieId": movie_dict["movie"]["movieId"],
"title": movie_dict["movie"]["title"],
"genres": movie_dict["movie"]["genres"],
"rating": movie_dict["rating"],
"timestamp": movie_dict["timestamp"]}))
return result_queries
Congratulations, you just created your first transformation procedure! Save it
and you should be able to see transformation rating() -> () among the
Detected procedures & transformations.
You can now Save and Close the module to get an overview of the module that lists procedures and their signature.
3. Create a stream
To add a stream in Memgraph Lab:
- Switch to Streams and Add New Stream.
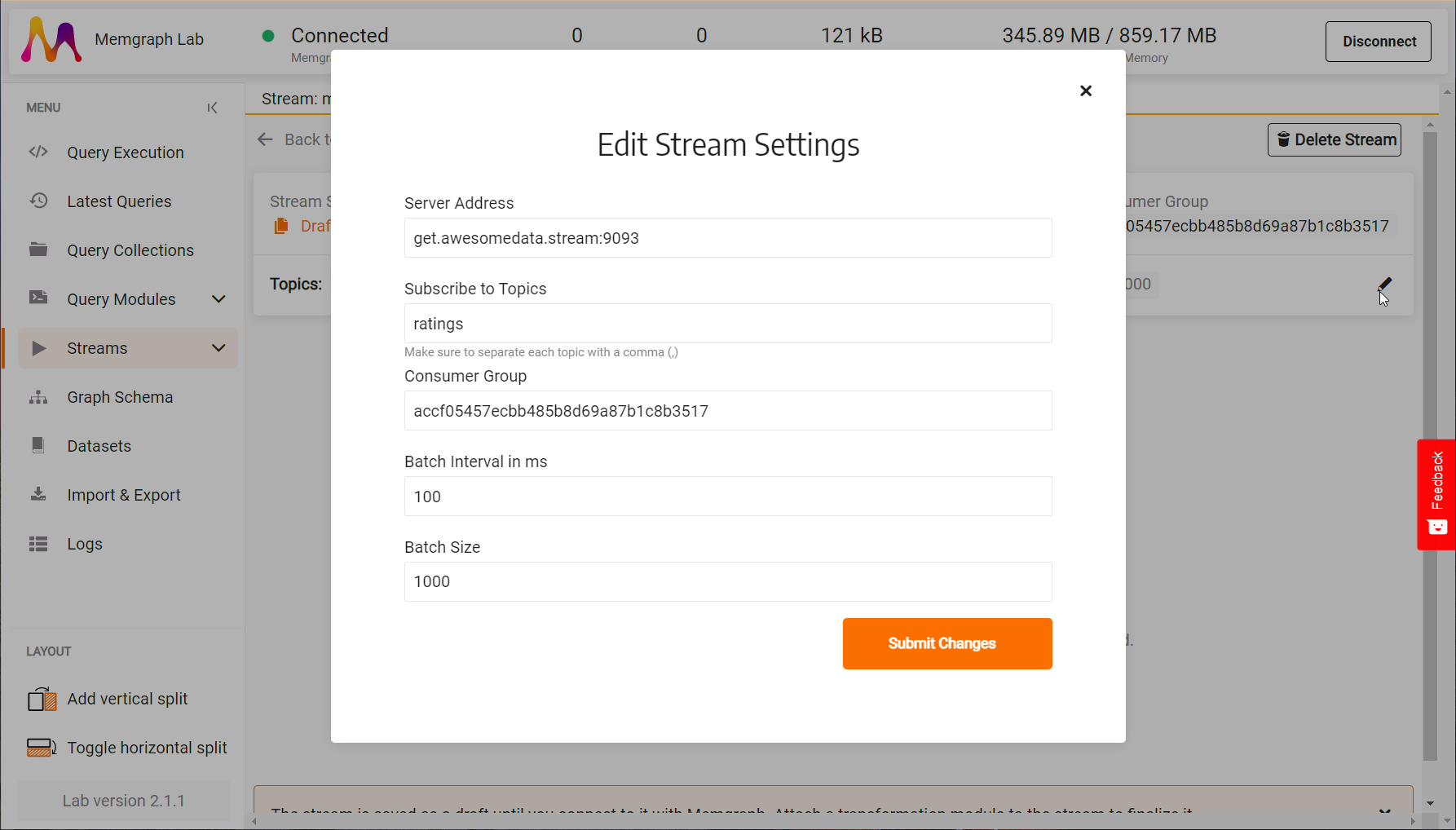
- Choose Kafka stream type, enter stream name
movielens, server addressget.awesomedata.stream:9093, and topicsratingas instructed on the Awesome Data Stream - Go to the Next Step.
- Click on Edit (pencil icon) to modify the Consumer Group to the one written on the Awesome Data Stream. As the streams are public, consumer groups need to be unique.
The stream configuration should look something like this:
4. Add a transformation module
To add the movielens Python transformation module you developed earlier to a stream:
- Click on Add Transformation Module.
- Click on Choose Transformation Module.
- Select the
movielenstransformation module - Check if the necessary transformation procedure
rating() -> ()is visible under Detected transformation functions on the right. - Select it and Attach to Stream.
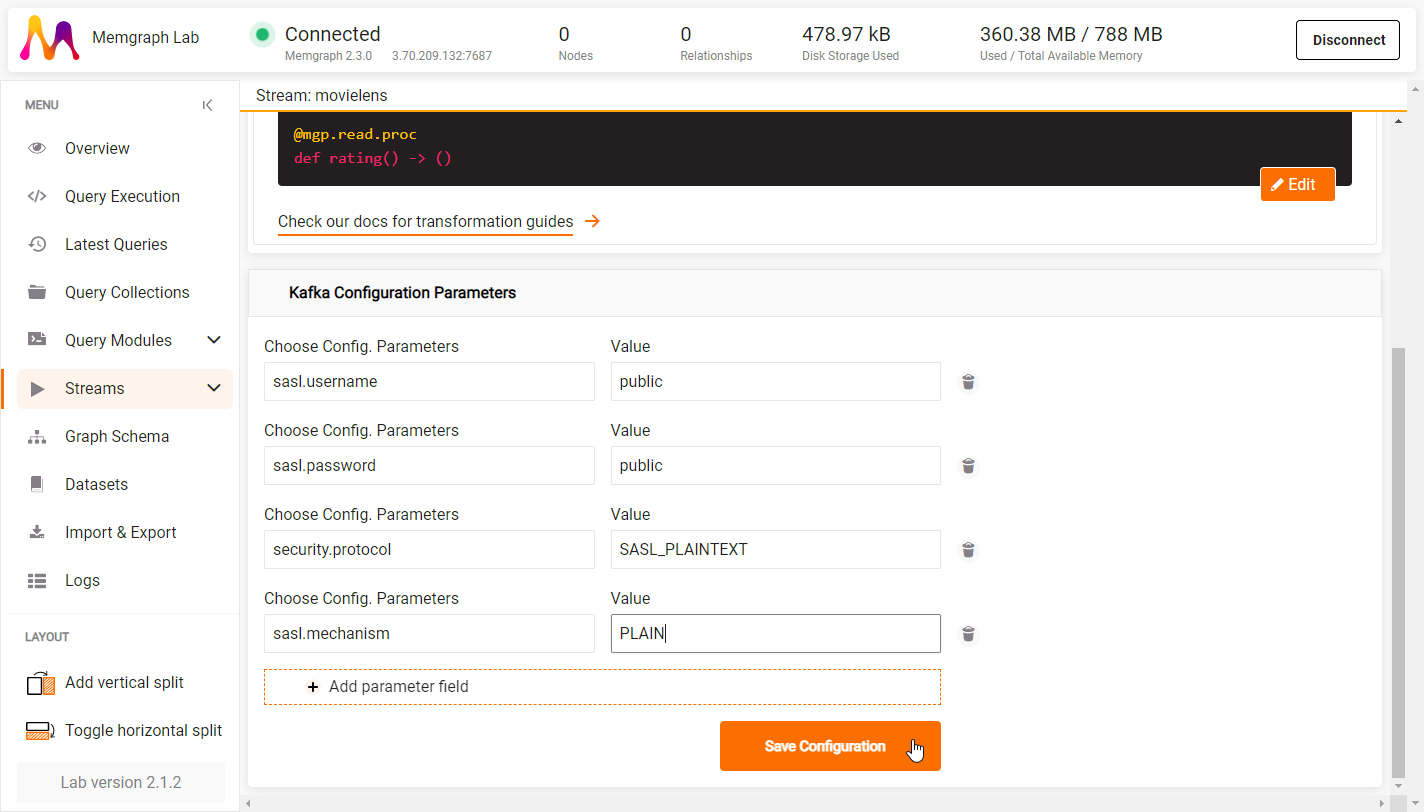
5. Set Kafka configuration parameters
Due to the nature of the public MovieLens Awesome Data Stream, you need to add additional Kafka configuration parameters:
- sasl.username: public
- sasl.password: public
- security.protocol: SASL_PLAINTEXT
- sasl.mechanism: PLAIN
In order to do so:
- In the Kafka Configuration Parameters + Add parameter field.
- Insert the parameter name and value.
- To add another parameter, Add parameter filed.
- Save Configuration once you have set all parameters.
6. Connect Memgraph to the stream and start ingesting the data
Once the stream is configured, you can Connect to Stream.
Memgraph will do a series of checks, ensuring that defined topics and transformation procedures are correctly configured. If all checks pass successfully, you can Start the stream. Once you start the stream, you will no longer be able to change configuration settings, just the transformation module.
The stream status changes to Running, and data is ingested into Memgraph. You can see the number of nodes and relationships rising as the data keeps coming in.
7. Analyze the streaming data
Switch to Query Execution and run a query to visualize the data coming in:
MATCH p=(n)-[r]-(m)
RETURN p LIMIT 100;
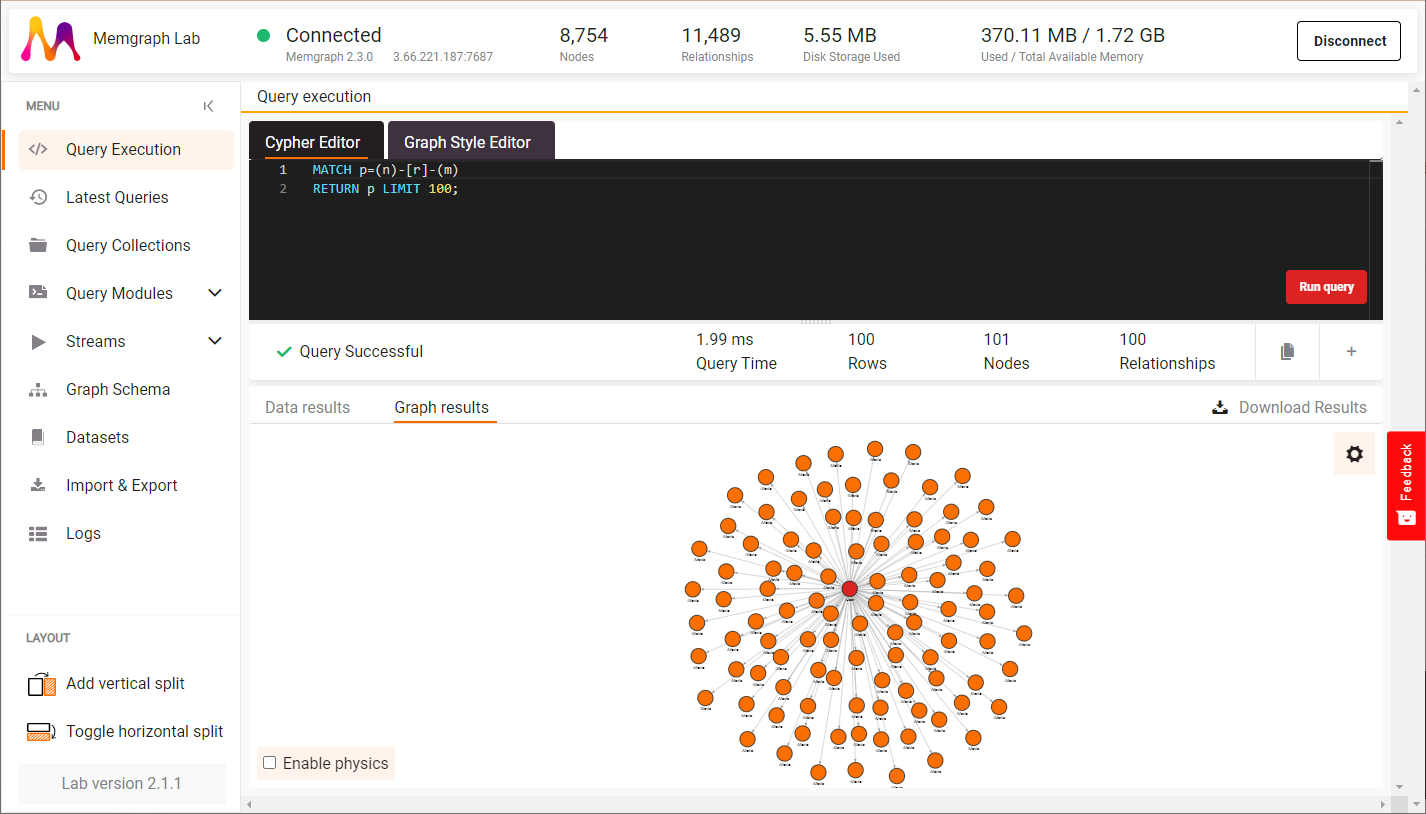
Congratulations! You have connected Memgraph to a Kafka stream. We've prepared queries that utilize the most powerful graph algorithms to gain every last bit of insight that data can provide. Let the querying begin!
If you are new to Cypher, check Cypher query language manual. You can also try using various graph algorithms and modules from our open-source repository MAGE to solve graph analytics problems, create awesome customized visual displays of your nodes and relationships with Graph Style Script.
You can also explore other data streams from the Awesome Data Stream site! Feel free to play around with the Python API some more and let us know what you are working on through our Discord server.
Above all - enjoy your graph database!